
Масштабируемое и принципиальное моделирование вознаграждений для LLM
Модели вознаграждений (RM) для больших языковых моделей (LLM) становятся все более важными для повышения их возможностей, таких как согласование с человеческими ожиданиями, долгосрочное мышление и адаптивность. Однако существует значительная проблема в создании точных сигналов вознаграждения в широких и менее структурированных областях.
Проблемы текущих моделей вознаграждений
Современные качественные модели вознаграждений в основном основаны на системах с правилами или верифицируемых задачах, таких как математика и программирование. В общих приложениях критерии вознаграждения более разнообразны и субъективны, что затрудняет создание четких и объективных оценок.
Решения для улучшения моделей вознаграждений
Исследования показывают, что общие модели вознаграждений могут быть улучшены с помощью методов, таких как:
- Модели с парными сравнениями, которые ограничены относительными оценками;
- Скалярные модели, которые могут испытывать трудности с разнообразной обратной связью;
- Генеративные модели вознаграждений (GRM), которые предлагают более гибкие и богатые результаты.
Новые подходы к моделированию вознаграждений
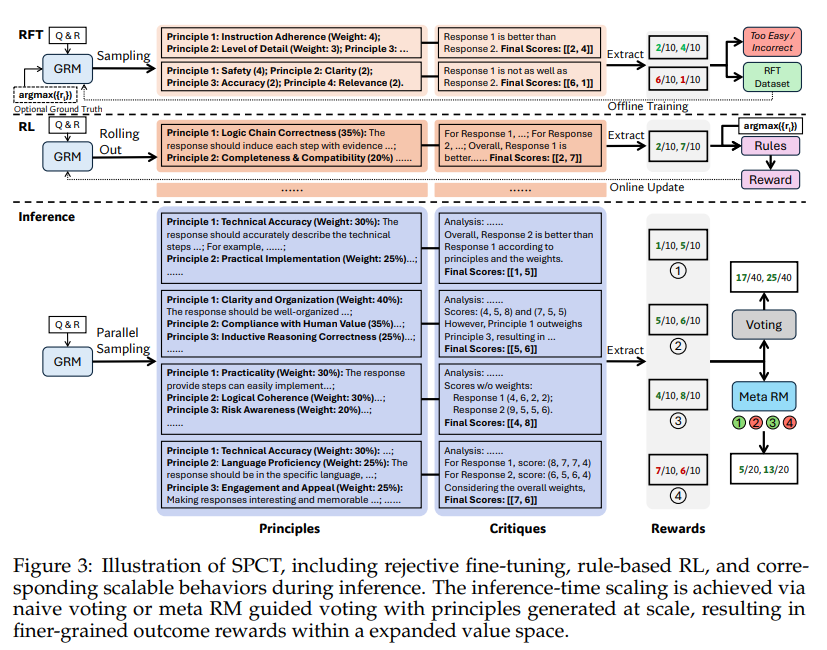
Исследователи из DeepSeek-AI и Университета Цинхуа разрабатывают новые методы, такие как Self-Principled Critique Tuning (SPCT), для улучшения масштабируемости моделей вознаграждений во время вывода. SPCT включает два этапа: начальная настройка для генерации принципов и критики, а также уточнение на основе правил.
Преимущества метода SPCT
Метод SPCT позволяет моделям GRM динамически генерировать принципы во время вывода, что способствует улучшению гранулярности вознаграждений. Параллельная выборка и голосование, поддерживаемые мета-моделью вознаграждений, помогают фильтровать низкокачественные результаты.
Результаты и достижения
Модели DeepSeek-GRM демонстрируют высокую эффективность и превосходят существующие эталонные методы, предлагая лучшее качество вознаграждений и масштабируемость. Исследования показывают, что использование мета-моделей вознаграждений значительно повышает производительность, достигая результатов, сопоставимых с гораздо более крупными моделями.
Практическое применение и будущее
Будущие работы будут сосредоточены на интеграции GRM в процессы обучения с подкреплением и масштабировании вместе с политическими моделями. Это обеспечит надежные офлайн-оценки и повысит общее качество вознаграждений.
Как использовать ИИ в бизнесе
Рассмотрите возможность автоматизации процессов и выявления моментов взаимодействия с клиентами, где искусственный интеллект может добавить максимальную ценность. Определите важные KPI для оценки влияния ваших инвестиций в ИИ на бизнес.
Рекомендации по внедрению ИИ
Начните с небольшого проекта, собирайте данные о его эффективности и постепенно расширяйте использование ИИ в вашей работе. Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru.
Пример решения на базе ИИ
Посмотрите на практический пример решения с использованием ИИ: продажный бот, который автоматизирует взаимодействия с клиентами круглосуточно и управляет всеми этапами клиентского пути.
Следите за последними новостями ИИ, подписавшись на наш Telegram.


















