Масштабируемое Обучение с Подкреплением с Проверяемыми Наградами
Обучение с подкреплением с проверяемыми наградами (RLVR) продемонстрировало свою эффективность в улучшении способностей больших языковых моделей (LLM) к рассуждению и программированию, особенно в областях, где структурированные ответы позволяют четко проверить правильность. Этот подход основывается на сигналах, основанных на ссылках, для определения соответствия ответа модели известному правильному ответу, обычно с помощью бинарных меток правильности или оценок. RLVR в основном применялся в таких областях, как математика и программирование, где проверка на основе правил или инструментов является простой. Однако расширение применения RLVR на более сложные и менее структурированные задачи оказалось трудным из-за проблем с проверкой открытых или неоднозначных ответов.
Генеративное Моделирование Наград
Недавние разработки направлены на расширение применения RLVR, вводя генеративное моделирование наград, где LLM используют свои генеративные способности для создания суждений и обоснований. Эти модели могут обучаться без детализированных обоснований, полагаясь на уверенность выводов проверяющего для генерации стабильных сигналов награды. Эта техника поддерживает обучение с подкреплением в задачах с шумными или неоднозначными метками.
Расширение Применения RLVR
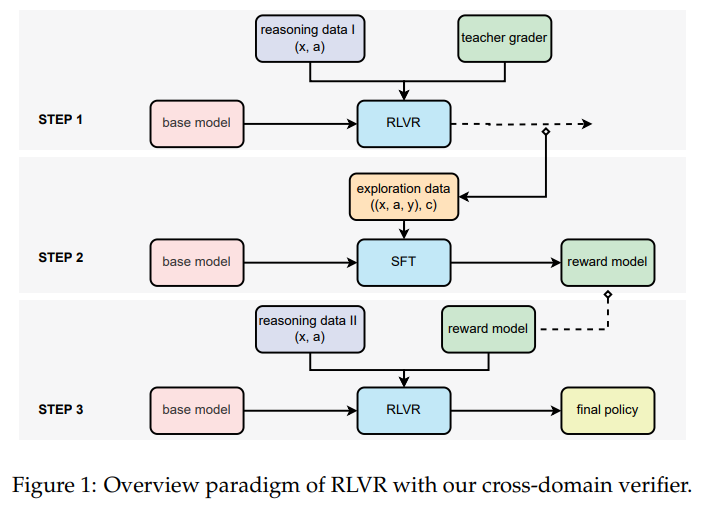
Исследователи из Tencent AI Lab и Университета Сучжоу изучают возможность расширения RLVR на сложные, неструктурированные области, такие как медицина, химия и образование. Они показывают, что бинарные суждения о правильности остаются последовательными между LLM, когда доступны экспертные ссылки. Для решения ограничений бинарных наград в свободных задачах они вводят мягкие, основанные на генеративных моделях сигналы награды.
Методология Исследования
Метод использует экспертные ответы для оценки наград в обучении с подкреплением. Ответы оцениваются с помощью генеративного LLM-проверяющего, который выдает бинарные (0/1) или мягкие награды на основе вероятности правильности. Награды нормализуются с использованием z-оценки для стабильного обучения и улучшения динамики обучения.
Результаты Исследования
Исследование использует два крупных китайских набора данных QA — один с 773k свободными математическими вопросами и другой с 638k много предметными вопросами уровня колледжа. Результаты показывают, что обучение с использованием наград на основе моделей превосходит методы, основанные на правилах, и супервайзинговую дообучение (SFT), особенно в задачах рассуждения.
Практические Решения для Бизнеса
Изучите, как технологии искусственного интеллекта могут трансформировать ваш подход к работе, например:
- Определите процессы, которые можно автоматизировать.
- Выявите моменты взаимодействия с клиентами, где ИИ может добавить наибольшую ценность.
- Определите важные KPI, чтобы убедиться, что ваши инвестиции в ИИ действительно оказывают положительное влияние на бизнес.
- Выберите инструменты, которые соответствуют вашим потребностям и позволяют вам настраивать их под ваши цели.
- Начните с небольшого проекта, соберите данные о его эффективности и постепенно расширяйте использование ИИ в вашей работе.
Контактная Информация
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram.
Пример Решения на Основе ИИ
Посмотрите на практический пример решения на основе ИИ: бот для продаж от itinai.ru, предназначенный для автоматизации взаимодействия с клиентами круглосуточно и управления взаимодействиями на всех этапах клиентского пути.