
«`html
Увеличение эффективности долгих контекстов в языковых моделях с помощью MInference
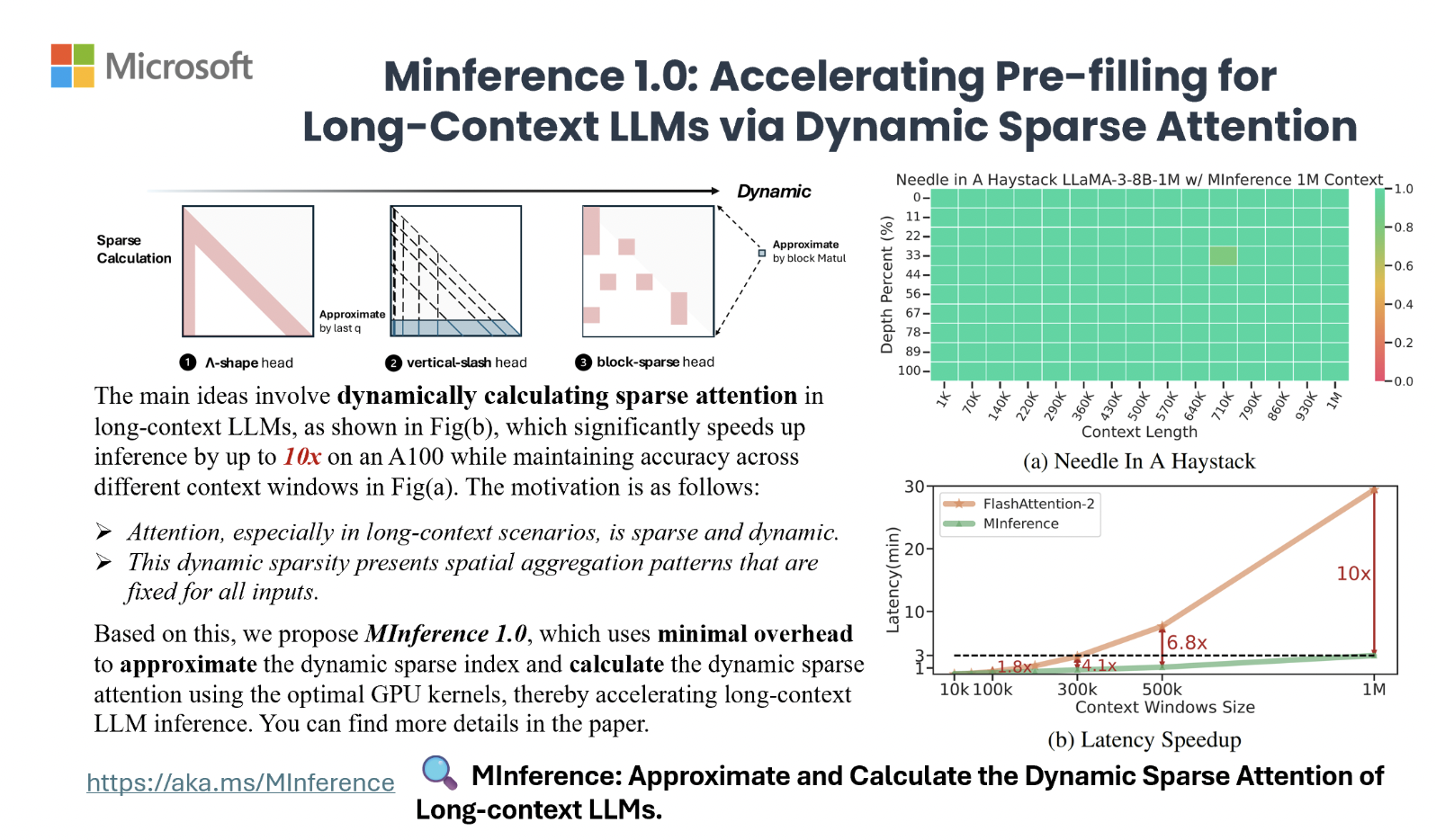
Вычислительные требования долгих языковых моделей (LLM), особенно с длинными запросами, затрудняют их практическое использование из-за квадратичной сложности механизма внимания. Однако MInference предлагает решение этой проблемы, позволяя существенно ускорить обработку длинных последовательностей в LLM и снизить задержки до 10 раз, сохраняя при этом точность.
Оптимизация вычислений для GPU
Метод MInference идентифицирует три различных паттерна внимания и оптимизирует разреженные вычисления для GPU, что позволяет сократить время предварительной обработки с 30 минут до 3 минут на одном GPU A100, не ухудшая точность.
Применение разреженного внимания
MInference использует динамическое разреженное внимание с конкретными пространственными агрегационными паттернами, такими как A-образное, Вертикально-прерывистое и Блочно-разреженное внимание, для оптимизации вычислений в LLM.
Практическое применение
Тестирование метода MInference на различных контекстных длинах показывает его превосходство в поддержании контекста и скорости обработки по сравнению с конкурирующими методами. Он также интегрируется эффективно с техниками сжатия кэша KV и значительно сокращает задержку, что подтверждает его практическую ценность в оптимизации производительности LLM.
Потенциал в других областях
Такие паттерны имеют потенциал в мульти-модальных и кодировщик-декодировщик LLM, что указывает на перспективные приложения ускорения этапа предварительной обработки.
Подробнее ознакомиться с исследованием можно в статье, репозитории на GitHub и демонстрации. Вся заслуга за это исследование принадлежит его авторам.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
«`



















