
«`html
Улучшение языковых моделей с помощью многокритериальной настройки
Многокритериальная настройка (MOFT) является важным этапом в обучении языковых моделей (LM) для их поведения в соответствии с человеческим этикетом. Сегодня MOFT включает в себя несколько целей из-за различных предпочтений и использований. Для преодоления ограничений однокритериальной настройки (SOFT) требуется MOFT для обучения многокритериальной LM. Для LM MOFT исследовались методы на основе подсказок и параметров. Методы на основе подсказок настраивают LM, включая веса вознаграждения в подсказке. Однако этот подход может быть менее эффективным в управлении моделью и чувствителен к представлению весов. Кроме того, нулевая MOFT может плохо справляться с промежуточными весами, которые не встречаются во время обучения.
Методы подхода к многокритериальной настройке
Два основных метода подхода к многокритериальной настройке — это подход на основе подсказок и подход на основе параметров. Подход на основе подсказок включает методы, такие как Personalized Soups (PS) и Rewarded Soups (RS). PS использует настраиваемые подсказки для персонализации LM на основе бинарных весов для различных вознаграждений. RS предлагает нулевой метод, усредняя параметры независимо обученных LM во время вывода. Недавнее исследование представляет встраивание весов вознаграждения в виде сингулярных значений в рамках AdaLoRA. Для перенастройки KL линейно смешиваются логиты между 𝜋ref и другим LM, обученным через SOFT с минимальным весом KL.
Улучшенная многокритериальная настройка
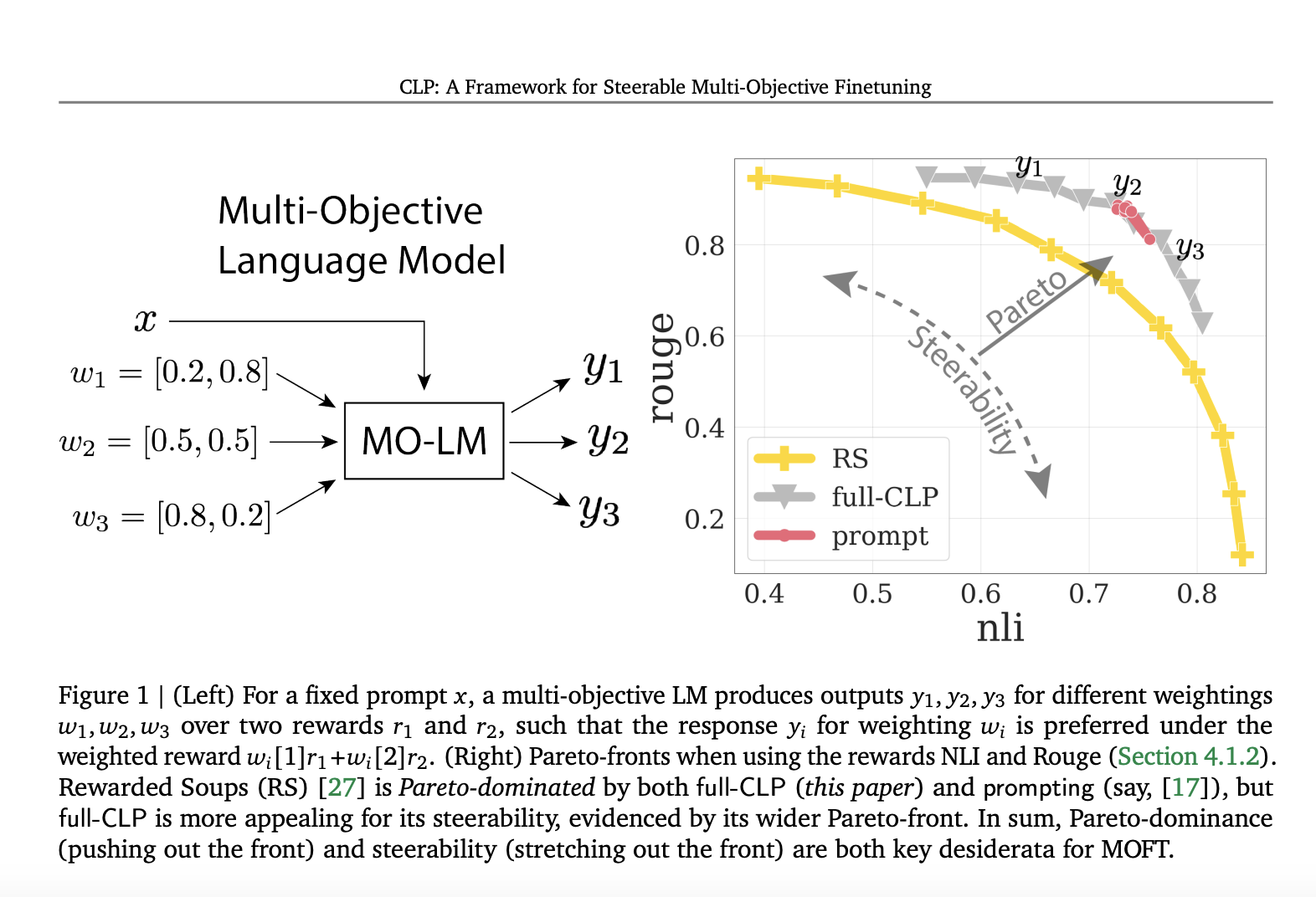
Команда из Google предложила общую структуру MOFT под названием Conditional Language Policy (CLP), использующую настройку пространства параметров и многозадачное обучение. Этот метод более управляем, чем чисто подсказочные техники, потому что он использует параметрическую настройку из RS. Кроме того, CLP производит более качественные ответы, чем нулевые методы, такие как RS, путем настройки на различные веса вознаграждения, сохраняя при этом ту же или более высокую управляемость. Команда провела серию экспериментов и обнаружила, что CLP превосходит Pareto RS и более управляем, чем подходы на основе подсказок MOFT. Он последовательно поддерживает эти преимущества в различных условиях, включая различный выбор вознаграждений и размеры моделей.
Применение CLP
Предложенный метод CLP изучает набор параметров, который может быть обработан в настроенную языковую модель для любых заданных весов вознаграждения и KL с использованием метода усреднения параметров. Алгоритм обучения выбирает ряд весов для улучшения своего Парето-фронта для всех весов сразу. Этот подход включает многозадачное обучение по различным весам, максимизируя цель MOFT. Автоматическая оценка с помощью Gemini 1.0 Ultra показывает, что CLP более адаптивен и генерирует лучшие ответы, чем существующие базовые варианты. Команда предложила новую теорию, показывающую, что нулевые методы могут быть почти Парето-оптимальными, когда оптимальные политики выравниваются для индивидуального вознаграждения.
Результаты и перспективы
Результаты бенчмаркинга были получены для нескольких настроек: Однократное вознаграждение, Множественный KL регуляризатор, Два вознаграждения, Фиксированный KL регуляризатор и Три вознаграждения, Фиксированный KL регуляризатор. В случае Однократного вознаграждения CLP в 2 раза более эффективен вычислительно, чем DeRa во время вывода, потому что DeRa делает два вызова LM на токен. Многозадачное обучение помогает этому методу улучшиться по сравнению с нулевым базовым RS. Кроме того, полный CLP и attn-CLP поддерживают более распределенный и управляемый Парето-фронт по сравнению с logit-CLP и подходом на основе подсказок. В целом, attn-CLP предлагает хороший баланс между Парето-фронтом и управляемостью, используя меньше параметров, чем текущие базовые варианты.
Заключение
В данной статье команда из Google представила Conditional Language Policy (CLP), гибкую структуру для MOFT, использующую многозадачное обучение и эффективную настройку параметров для создания адаптивных языковых моделей, способных эффективно балансировать различные индивидуальные вознаграждения. Статья включает обширные исследования и анализ факторов, способствующих развитию управляемых LM в рамках структуры CLP. Команда также предложила теоретические результаты, чтобы показать работу нулевых методов и необходимость многозадачного обучения для приближенного к оптимальному поведению. Будущие исследования включают другие механизмы настройки, такие как мягкие токены, автоматизацию настройки распределений весов и работу с нелинейной скаляризацией вознаграждения.
Проверьте статью здесь. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашей группе в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Оригинальная статья: This Paper from Google DeepMind Presents Conditioned Language Policies (CLP): A Machine Learning Framework for Finetuning Language Models on Multiple Objectives.