
«`html
Новый метод слабо-надзорного предварительного обучения для моделей компьютерного зрения с использованием общедоступных веб-масштабных данных изображений и текста
В последнее время контрастное обучение стало мощной стратегией для обучения моделей эффективным визуальным представлениям путем выравнивания вложений изображений и текста. Однако одной из сложностей контрастного обучения является вычислительная сложность парной схожести между парами изображений и текста, особенно при работе с крупными наборами данных.
Практические решения и ценность
В недавних исследованиях команда исследователей представила новый метод предварительного обучения моделей компьютерного зрения с использованием веб-масштабных данных изображений и текста в слабо надзорном режиме. Названный CatLIP (Categorical Loss for Image-text Pre-training), этот подход решает компромисс между эффективностью и масштабируемостью на веб-масштабных наборах данных изображений и текста с слабой разметкой.
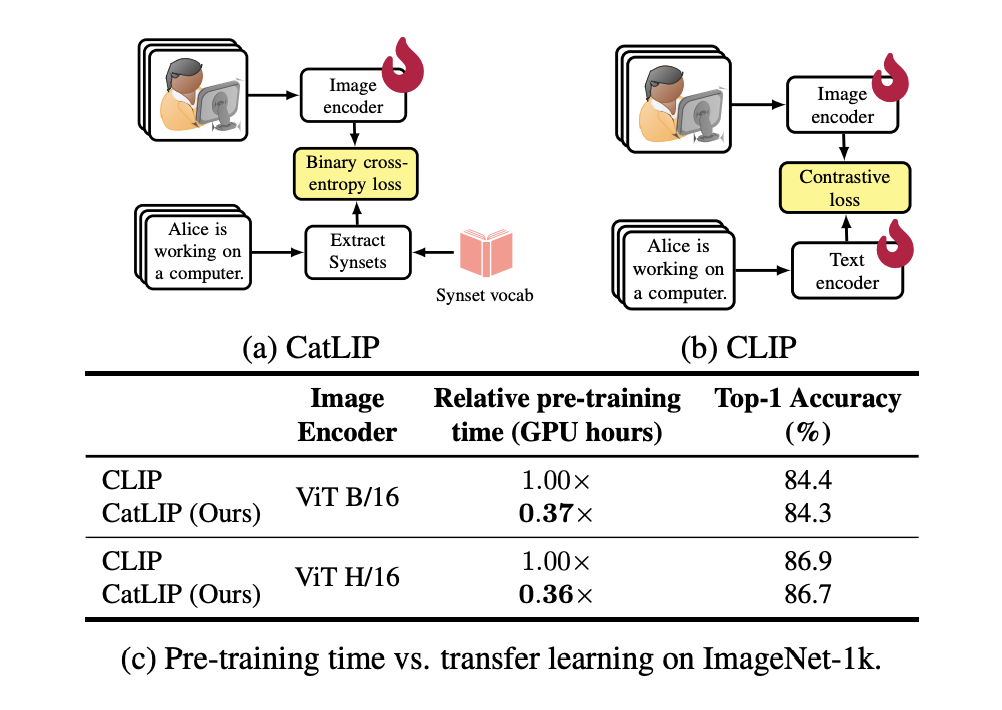
Путем извлечения меток из текстовых подписей CatLIP рассматривает предварительное обучение изображений и текста как задачу классификации. Команда поделилась, что этот метод поддерживает производительность на последующих задачах, таких как классификация ImageNet-1k, и намного эффективнее обучается, чем CLIP. Были продемонстрированы комплексные тесты для подтверждения эффективности CatLIP.
Эффективность CatLIP была оценена командой через комплексный набор тестов, включающих различные задачи компьютерного зрения, такие как обнаружение объектов и сегментация изображений. Они показали, что этот подход сохраняет высококачественные представления, которые хорошо себя проявляют в различных визуальных тестах, даже при изменении парадигмы обучения.
Команда подвела итоги своих основных вкладов:
- Переосмысление данных изображений и текста как задачи классификации представляет уникальный способ ускорения предварительного обучения моделей компьютерного зрения на таких данных.
- CatLIP работает лучше с масштабированием данных и моделей, что особенно заметно при тестировании с небольшими объемами данных изображений и текста. При обучении модели в течение длительного времени по сравнению с традиционными методами контрастного обучения, такими как CLIP, модель показывает значительно лучшие результаты.
- Используя вложения, связанные с целевыми метками из слоя классификации, команда предложила метод, который позволяет предварительно обученной модели передавать информацию на целевые задачи эффективным способом. С помощью этого метода вложения, полученные во время предварительного обучения, могут быть использованы для инициализации слоя классификации в последующих задачах, обеспечивая эффективное обучение на основе данных.
- Через обширные тесты, охватывающие множество последующих задач, включая распознавание объектов и семантическую сегментацию, команда продемонстрировала эффективность представлений, которые изучил CatLIP. CatLIP достигает схожей производительности с CLIP, но с гораздо более коротким временем предварительного обучения, что подтверждается временем предварительного обучения, которое в 2,7 раза быстрее на наборе данных DataComp-1.3B.
В заключение, путем переформулирования задачи как задачи классификации, это исследование предлагает новый подход к предварительному обучению моделей компьютерного зрения на веб-масштабных данных изображений и текста. Эта стратегия не только сохраняет качество представлений в различных визуальных задачах, но также значительно ускоряет время обучения.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш бюллетень.
Не забудьте присоединиться к нашему 40k+ ML SubReddit
Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`



















