
«`html
Уникальный метод Strategic Chain-of-Thought (SCoT): как улучшить производительность и рассуждения крупных моделей языка (LLM) с помощью стратегического выявления
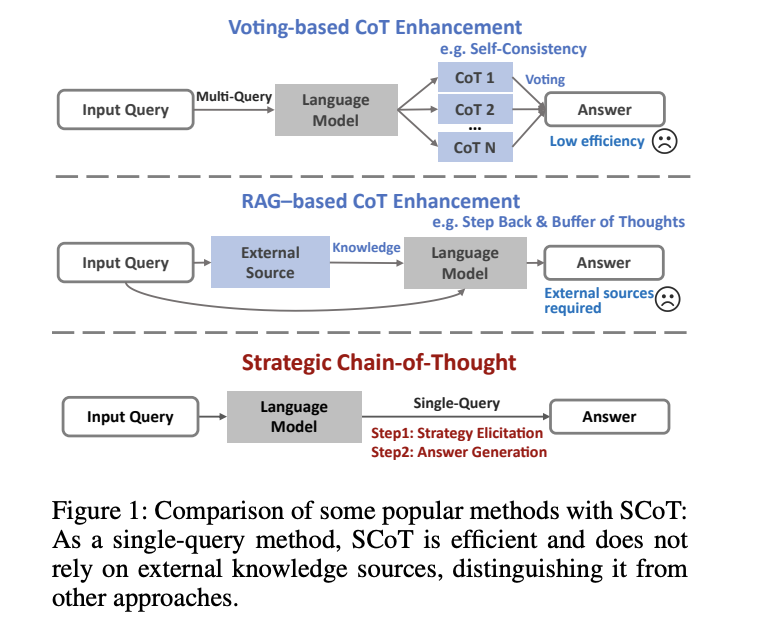
Один из важных тактик для улучшения способности к рассуждению больших языковых моделей (LLM) — это парадигма Chain-of-Thought (CoT). Путем поощрения моделей разделять задачи на промежуточные шаги, подобно тому, как люди методично подходят к сложным проблемам, CoT улучшает процесс решения проблем. Этот метод доказал свою чрезвычайную эффективность в ряде приложений, что привело к его ключевому положению в сообществе обработки естественного языка (NLP).
Проблема с CoT и решение
Несмотря на успех CoT, его крупным недостатком является то, что он не всегда приводит к рассуждениям высокого уровня. Производительность рассуждения может страдать из-за неоптимальных путей, создаваемых LLM с применением CoT. Это происходит потому, что LLM не всегда генерируют промежуточные шаги с использованием логической или эффективной методики рассуждения, что приводит к изменчивости в конечных результатах.
Недавно была разработана стратегическая техника Chain-of-Thought (SCoT) как средство устранения этой проблемы за счет повышения качества и последовательности рассуждений в LLM. Добавляя стратегические знания перед созданием путей рассуждения, SCoT вводит организованный метод рассуждения. Это стратегическое обучение помогает убедиться в том, что промежуточные фазы модели имеют смысл и соответствуют более эффективному способу решения проблем.
Эффективность SCoT и результаты
Эксперименты были проведены на восьми сложных наборах данных для оценки эффективности SCoT. Результаты показали большое обещание и значительные улучшения производительности. На наборе данных GSM8K, уделяющем внимание математическому рассуждению, модель показала улучшение точности на 21,05%. На наборе данных Tracking Objects, связанном с пространственным рассуждением, модель достигла увеличения на 24,13%. Модель Llama3-8b использовалась для наблюдения этих улучшений, демонстрируя адаптивность SCoT в различных сценариях рассуждения.
Заключение и приглашение к действию
В заключение, SCoT представляет собой значительное развитие в рассуждении LLM. Он преодолевает основные недостатки традиционных техник Chain-of-Thought путем включения стратегической информации и улучшения процедуры. Этот методический подход не только увеличивает точность и надежность рассуждений, но также имеет потенциал изменить способ, которым LLM решают сложные задачи рассуждения в различных областях.
Подробнее о научной статье вы можете прочитать здесь.
«`
Если вам нужна консультация по внедрению искусственного интеллекта, обращайтесь к нам по ссылке здесь. Следите за новостями об искусственном интеллекте в нашем Телеграм-канале тут или в Twitter @itinairu45358
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как искусственный интеллект может изменить ваши процессы с решениями от AI Lab itinai.ru — будущее уже здесь!
«`





















