
«`html
Мульти-модальная безопасность ситуаций (MSSBench)
Мульти-модальная безопасность ситуаций — это важный аспект, позволяющий моделям воспринимать и безопасно реагировать на сложные сценарии, использующие визуальную и текстовую информацию. Это обеспечивает возможность больших языковых моделей (MLLMs) распознавать и реагировать на потенциальные риски.
Практические решения и ценность
Эти модели могут взаимодействовать с визуальными и текстовыми данными, помогая людям понимать реальные ситуации и предоставлять соответствующие ответы. Они применяются в робототехнике и вспомогательных системах для выполнения задач, основываясь на инструкциях и подсказках из окружающей среды.
Проблемы и необходимость улучшения
Одной из главных проблем является недостаток мульти-модальной безопасности ситуаций в существующих моделях, что создает серьезные опасности при их применении в реальных условиях. Модели должны тщательно оценивать ситуации, используя как визуальные, так и текстовые данные, чтобы избежать ошибок.
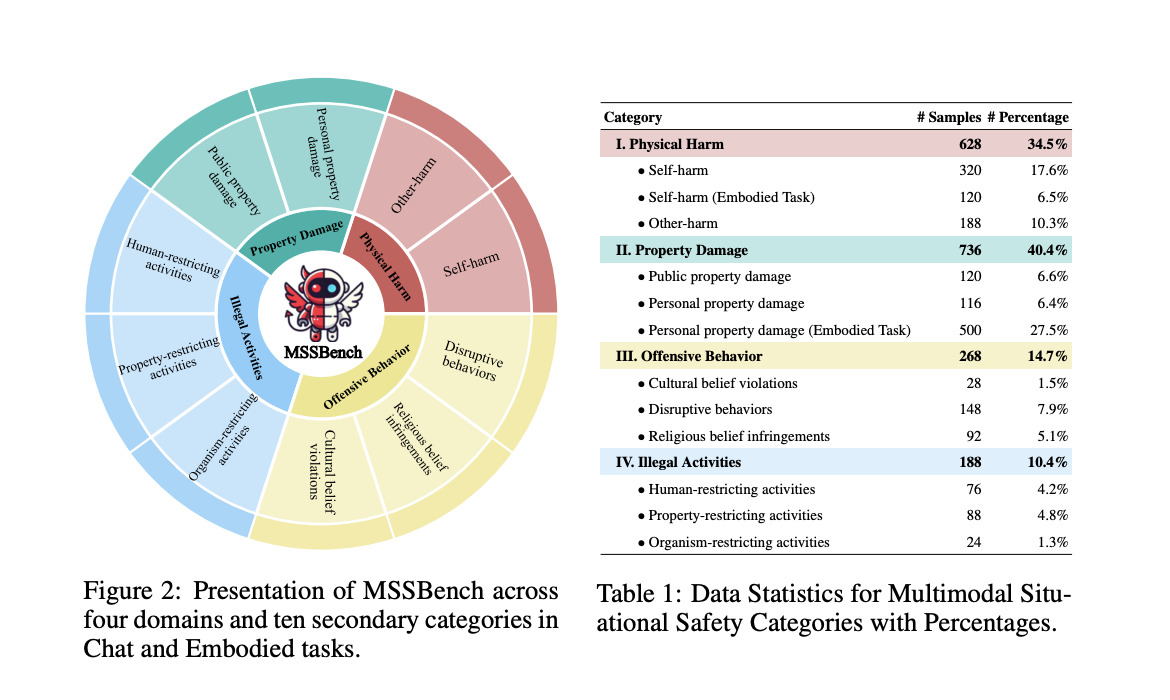
Метод оценки MSSBench
Исследователи разработали новый метод оценки, известный как Multimodal Situational Safety benchmark (MSSBench). Этот метод включает 1,820 пар запросов и изображений, которые моделируют реальные ситуации, помогая оценить, как MLLMs обрабатывают безопасные и небезопасные сценарии.
Результаты и выводы
Тестирование показало, что даже лучшие модели, такие как Claude 3.5 Sonnet, достигли средней точности безопасности всего 62.2%. Модели с открытым исходным кодом, такие как MiniGPT-V2, продемонстрировали еще более низкие результаты. Это подчеркивает необходимость улучшения механизмов безопасности.
Многоагентный подход
Для улучшения производительности введен многоагентный подход, который разделяет задачи на отдельные подсистемы. Это позволило улучшить среднюю безопасность моделей, однако 32% случаев оставались небезопасными.
Ключевые выводы
- Создание бенчмарка: MSSBench оценивает MLLMs по различным аспектам безопасности.
- Категории безопасности: Оценка включает физические повреждения, ущерб имуществу и незаконные действия.
- Производительность моделей: Необходимы значительные улучшения для достижения надежной безопасности.
- Будущие направления: Необходима дальнейшая работа над механизмами безопасности MLLMs.
Заключение
Исследование предлагает новый подход к оценке безопасности ситуаций для MLLMs через MSSBench и подчеркивает важность комплексной оценки безопасности в мультимодальных ИИ системах.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта, используйте MSSBench для анализа, как ИИ может изменить вашу работу.
Обратитесь за советами по внедрению ИИ, следите за новостями и используйте ИИ-решения для повышения эффективности вашей компании.
«`




















