
«`html
Научное открытие и искусственный интеллект
Научное открытие было основой человеческого прогресса в течение веков, традиционно полагаясь на ручные процессы. Однако появление больших языковых моделей (LLM) с продвинутыми способностями рассуждения и возможностью взаимодействия с внешними инструментами и агентами открыло новые возможности для автономных систем открытий. Основной вызов заключается в разработке полностью автономной системы, способной генерировать и проверять гипотезы в области данных. Недавние исследования показали многообещающие результаты в этом направлении, но полный потенциал LLM в научных открытиях остается неопределенным. Ученые сталкиваются с задачей исследования и расширения возможностей этих ИИ-систем для революционизации научного процесса, что потенциально может ускорить темп открытий и инноваций в различных областях.
Автоматизированные системы научных открытий
Предыдущие попытки автоматизированных данных-приводимых открытий варьировались от ранних систем, таких как Bacon, который подгонял уравнения к идеализированным данным, до более продвинутых решений, таких как AlphaFold, способный решать сложные проблемы реального мира. Однако эти системы часто полагались на специфические наборы данных и заранее построенные конвейеры. Инструменты AutoML, такие как Scikit и облачные решения, сделали значительные шаги в автоматизации рабочих процессов машинного обучения, но их наборы данных в основном используются для обучения моделей, а не для задач открытий без конкретного завершения. Подобно этому, наборы данных и программные пакеты для статистического анализа, такие как Tableaux, SAS и R, поддерживают анализ данных, но ограничены своими возможностями. Набор данных QRData представляет собой шаг к изучению возможностей LLM в статистическом и причинном анализе, но он фокусируется на четко определенных вопросах с уникальными, в основном числовыми ответами. Эти существующие подходы, хотя и ценны, должны предоставить всеобъемлющее решение для автоматизации всего процесса открытий, включая идеализацию, семантическое рассуждение и проектирование конвейера.
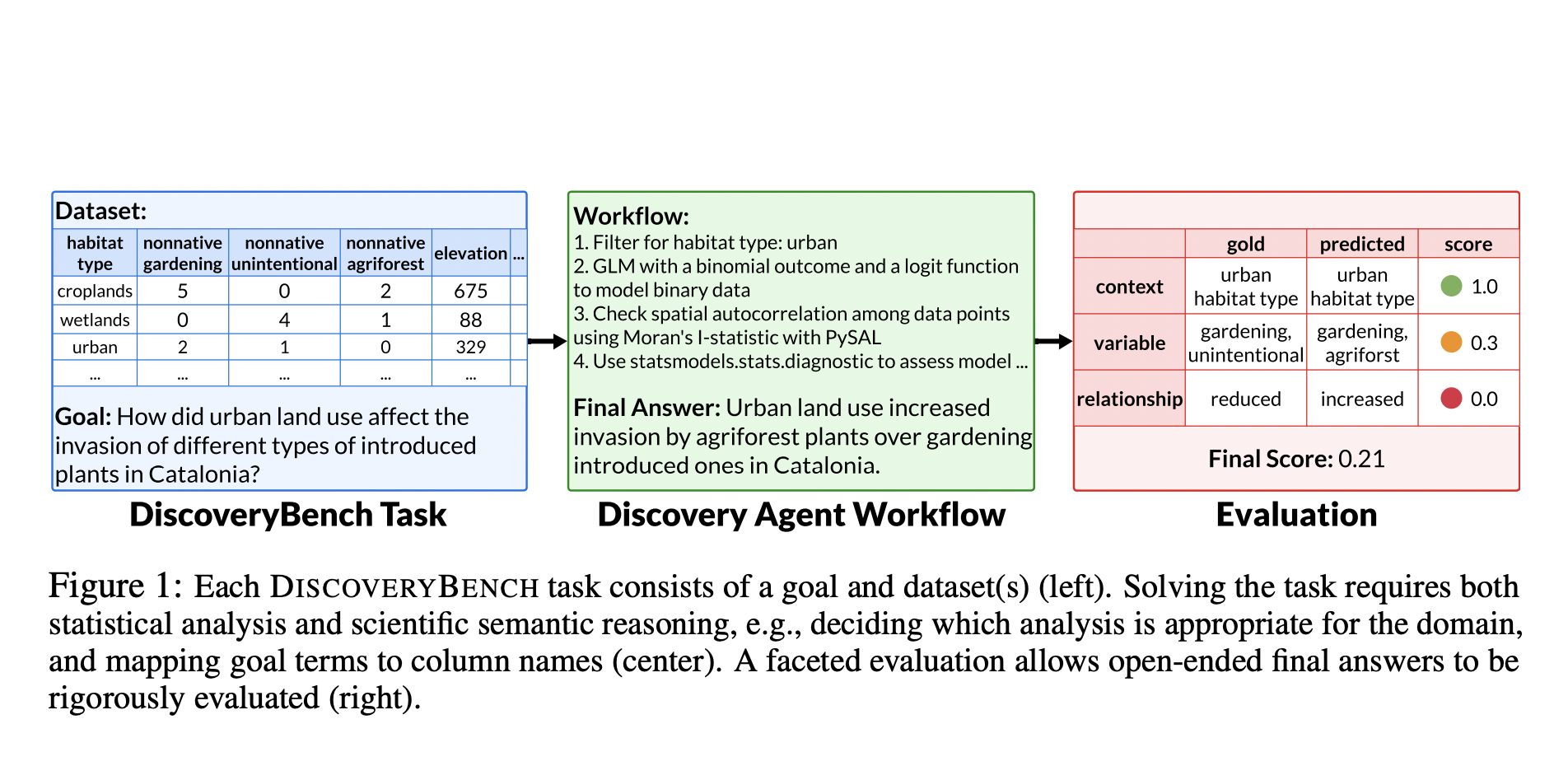
DISCOVERYBENCH: оценка возможностей LLM
Исследователи из Allen Institute for AI, OpenLocus и Университета Массачусетса в Амхерсте предлагают DISCOVERYBENCH, который направлен на систематическую оценку возможностей современных больших языковых моделей (LLM) в автоматизированных данных-приводимых открытиях. Этот бенчмарк решает проблемы разнообразия в реальных данных-приводимых открытиях в различных областях путем введения прагматической формализации. Он определяет задачи открытий как поиск отношений между переменными в конкретном контексте, где описание этих элементов может не соответствовать языку набора данных. Такой подход позволяет систематически и воспроизводимо оценивать широкий спектр реальных проблем путем использования ключевых аспектов процесса открытий.
DISCOVERYBENCH отличается от предыдущих наборов данных для статистического анализа или AutoML путем включения научного семантического рассуждения. Это включает выбор соответствующих техник анализа для конкретных областей, очистку и нормализацию данных, а также сопоставление терминов цели с переменными набора данных. Задачи обычно требуют многоэтапных рабочих процессов, охватывающих более широкий конвейер данных-приводимых открытий, а не фокусирующихся исключительно на статистическом анализе. Такой всеобъемлющий подход делает DISCOVERYBENCH первым крупномасштабным набором данных для изучения возможностей LLM во всем процессе открытий.
В этом методе исследователи начинают с формализации данных-приводимых открытий путем введения структурированного подхода к представлению и оценке гипотез. Он определяет гипотезы как декларативные предложения, подлежащие проверке через наборы данных, разбивая их на контексты, переменные и отношения. Ключевым новшеством является Гипотезное семантическое дерево, иерархическая структура, представляющая сложные гипотезы с взаимосвязанными переменными. Это дерево позволяет кодировать несколько гипотез в одной структуре. Метод также формализует наборы данных задач как коллекции кортежей, поддерживающих несколько гипотезных семантических деревьев с различными степенями наблюдаемости. Эта структура обеспечивает гибкий, но строгий подход к представлению и оценке сложных проблем открытий, позволяя систематически оценивать автоматизированные системы открытий.
DISCOVERYBENCH состоит из двух основных компонентов: DB-REAL и DB-SYNTH. DB-REAL включает реальные гипотезы и рабочие процессы, извлеченные из опубликованных научных статей в шести областях: социологии, биологии, гуманитарных наук, экономики, инженерии и мета-науки. Он включает задачи, которые часто требуют анализа нескольких наборов данных, с рабочими процессами от базовой подготовки данных до продвинутого статистического анализа. С другой стороны, DB-SYNTH — это синтетический бенчмарк, который позволяет контролируемую оценку моделей. Он использует большие языковые модели для генерации разнообразных областей, построения семантических гипотезных деревьев, создания синтетических наборов данных и формулирования задач открытий различной сложности. Такой двойной подход позволяет DISCOVERYBENCH улавливать как сложность реальных проблем открытий, так и систематическое изменение, необходимое для всесторонней оценки моделей.
Исследование оценивает несколько агентов открытий, работающих на различных языковых моделях (GPT-4o, GPT-4p и Llama-3-70B) на наборе данных DISCOVERYBENCH. Агенты включают CodeGen, ReAct, DataVoyager, Reflexion (Oracle) и NoDataGuess. Результаты показывают, что общая производительность низкая для всех пар агент-LLM как для DB-REAL, так и для DB-SYNTH, подчеркивая сложность бенчмарка. Удивительно, что продвинутые рассуждения (ReAct) и планирование с самокритикой (DataVoyager) не значительно превосходят простого агента CodeGen. Однако Reflexion (Oracle), использующий обратную связь для улучшения, показывает заметные улучшения по сравнению с CodeGen. Исследование также показывает, что нерефлексирующие агенты в основном решают самые простые случаи, и производительность на DB-REAL и DB-SYNTH схожа, подтверждая способность синтетического бенчмарка улавливать сложности реального мира.
DISCOVERYBENCH представляет собой значительное достижение в оценке автоматизированных систем данных-приводимых открытий. Этот всеобъемлющий бенчмарк включает 264 реальных задач открытий, извлеченных из опубликованных научных рабочих процессов, дополненных 903 синтетически созданными задачами, предназначенными для оценки агентов открытий на различных уровнях сложности. Несмотря на использование передовых фреймворков рассуждения, работающих на продвинутых больших языковых моделях, лучший агент достигает лишь 25% успеха. Это скромное выполнение подчеркивает сложность автоматизированных научных открытий и указывает на значительные возможности для улучшения в этой области. Предоставляя этот своевременный и надежный оценочный фреймворк, DISCOVERYBENCH стремится стимулировать увеличение интереса и исследовательских усилий в разработке более надежных и воспроизводимых автономных систем научных открытий с использованием больших генеративных моделей.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 46 тыс. подписчиков на ML SubReddit.
Пост опубликован на MarkTechPost.
«`


















