
«`html
Can LLMs Visualize Graphics? Assessing Symbolic Program Understanding in AI
Большие языковые модели (LLM) продемонстрировали способность генерировать общие компьютерные программы, что дает понимание структуры программы. Однако сложно определить их истинные возможности, особенно в поиске задач, которые они не видели во время обучения. Критически важно определить, способны ли LLM действительно «понимать» символьные графические программы, которые генерируют визуальное содержимое при выполнении. Это понимание определяется как способность понимать семантическое содержимое отображенного изображения только на основе исходного текстового ввода программы. Этот метод включает в себя ответы на вопросы о содержании изображения без его непосредственного просмотра, что легко с визуальным вводом, но гораздо сложнее, когда полагаешься только на текст программы.
Практические решения и ценность:
Исследования символьных графических программ в основном сосредоточены на процедурном моделировании для 2D форм и 3D геометрии. Эти программы, такие как Constructive Solid Geometry (CSG), Computer-Aided Design (CAD) и Scalable Vector Graphics (SVG), предоставляют четкое и интерпретируемое представление визуального содержимого. Кроме того, LLM были применены к различным программным задачам, таким как извлечение кода, автоматизированное тестирование и генерация; однако понимание символьных графических программ существенно отличается, поскольку их семантическое значение часто определяется визуально. Существующие бенчмарки для LLM сосредоточены на понимании программ без графики, в то время как модели видео-языка оцениваются с использованием мультимодальных наборов данных для задач, таких как подписывание изображений и визуальное вопросно-ответное взаимодействие.
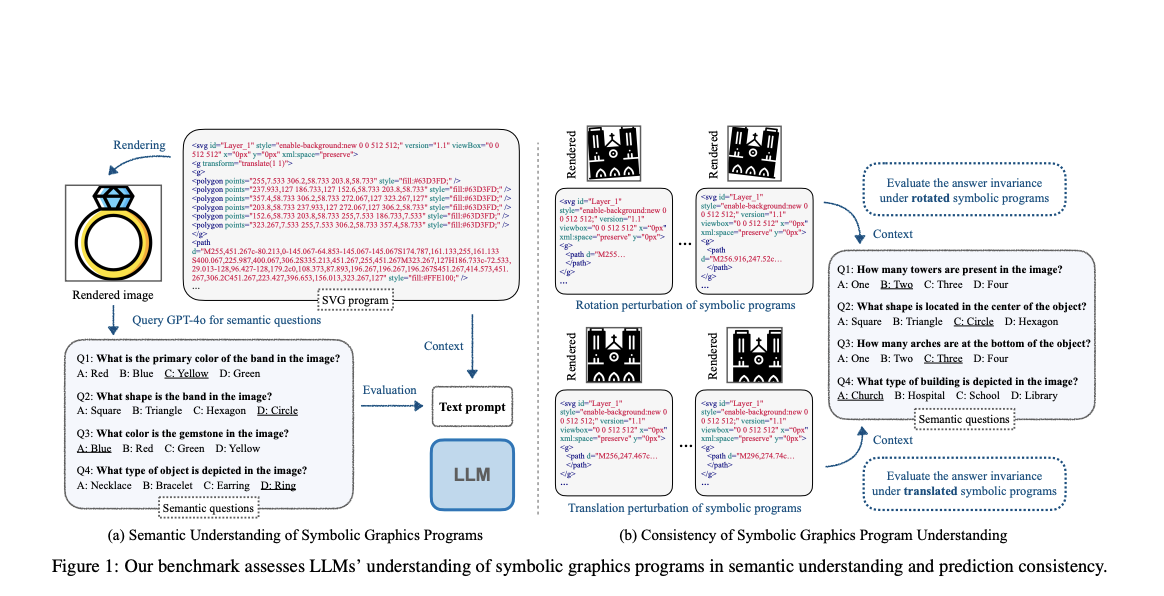
Исследователи из Института интеллектуальных систем имени Макса Планка в Тюбингене, Университета Кембриджа и Массачусетского технологического института предложили новый подход для оценки и улучшения понимания LLM символьных графических программ. Для оценки семантического понимания LLM и их последовательности в интерпретации программ SVG (векторная графика 2D) и CAD (2D/3D объекты) был представлен бенчмарк под названием SGP-Bench. Кроме того, был разработан новый метод тонкой настройки на основе собранного набора данных по следованию инструкциям, называемый символьная настройка инструкций, для улучшения производительности. Также созданный исследователями символьный набор данных MNIST показывает существенные различия между пониманием символьных графических программ LLM и человеком.
Процесс создания бенчмарка для оценки понимания LLM символьных графических программ использует масштабируемую и эффективную платформу. Он использует мощную модель видео-языка (GPT-4o) для генерации семантических вопросов на основе отображенных изображений символьных программ. Кроме того, человеческие аннотаторы проверяют качество и точность этих автоматически сгенерированных пар вопрос-ответ. Этот подход сокращает необходимые ручные усилия по сравнению с традиционными методами создания данных. Процесс для программ SVG и 2D CAD прост, поскольку они непосредственно производят 2D изображения, но в программе 3D CAD 3D модели сначала преобразуются в 2D изображения из нескольких фиксированных позиций камеры.
Оценка понимания LLM символьных графических программ проводится на наборе данных SGP-MNIST, который состоит из 1 000 программ SVG, отображающих изображения цифр, похожие на MNIST, с 100 программами на цифру (0-9). В то время как люди легко распознают изображения, LLM нашли крайне сложным интерпретировать символьные программы. Даже продвинутая модель GPT-4o показала лишь незначительное улучшение по сравнению с случайным угадыванием. Этот яркий контраст между производительностью человека и LLM подчеркивает значительный разрыв в том, как машины обрабатывают и понимают символьные представления визуальной информации по сравнению с людьми.
В заключение, исследователи представляют новый способ оценки LLM путем оценки их способности понимать изображения непосредственно из их символьных графических программ без визуального ввода. Исследователи создали SGP-Bench, бенчмарк, который эффективно измеряет, насколько хорошо LLM выполняют эту задачу. Они также представили Symbolic Instruction Finetuning (SIT) для улучшения способности LLM интерпретировать графические программы. Эти исследования помогают представить более ясную картину возможностей LLM и способствуют созданию разнообразных задач для оценки. Будущие исследования включают изучение того, как LLM понимают семантику в этой области и работу над разработкой продвинутых методов для улучшения их производительности в этих задачах.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему Телеграм-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу более чем 48 000 подписчиков на Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Arcee AI представляет Arcee Swarm: революционное сочетание агентов MoA Architecture, вдохновленное кооперативным интеллектом, найденным в самой природе.
Опубликовано на MarkTechPost.
«`



















