
«`html
Применение Generalizable Reward Model (GRM) в искусственном интеллекте
Предварительно обученные большие модели показали впечатляющие возможности в различных областях. Недавние исследования сосредотачиваются на обеспечении соответствия этих моделей человеческим ценностям и предотвращении вредных поведенческих шаблонов. Для достижения этой цели ключевыми являются методы выравнивания, важными из которых являются надзорное дообучение (SFT) и обучение с подкреплением на основе обратной связи от людей (RLHF). RLHF полезно для обобщения модели вознаграждения на новые пары запрос-ответ. Однако он сталкивается с проблемой обучения модели вознаграждения, которая хорошо работает с невидимыми данными. Одной из распространенных проблем является «переоптимизация» или «взлом вознаграждения». Увеличение размера модели вознаграждения и объема тренировочных данных может помочь решить эту проблему, но это непрактично в реальных ситуациях.
Два подхода в связанной работе
Первый подход — Моделирование вознаграждения, где модели вознаграждения обучаются на данных предпочтений людей для направления процесса RLHF или оптимизации запросов. Недавние исследования сосредотачиваются на разработке более эффективных моделей вознаграждения для улучшения производительности больших языковых моделей (LLM) в RLHF. Это включает улучшение моделирования вознаграждения путем улучшения качества или количества данных предпочтений. Второй подход — Смягчение переоптимизации в RLHF, где модели вознаграждения часто переобучаются и плохо обобщаются за пределы тренировочных данных, что приводит к проблеме переоптимизации. Можно наказывать слишком уверенные выводы модели, используя сглаживание меток или регуляризацию SFT для устранения этой проблемы.
Результаты исследования
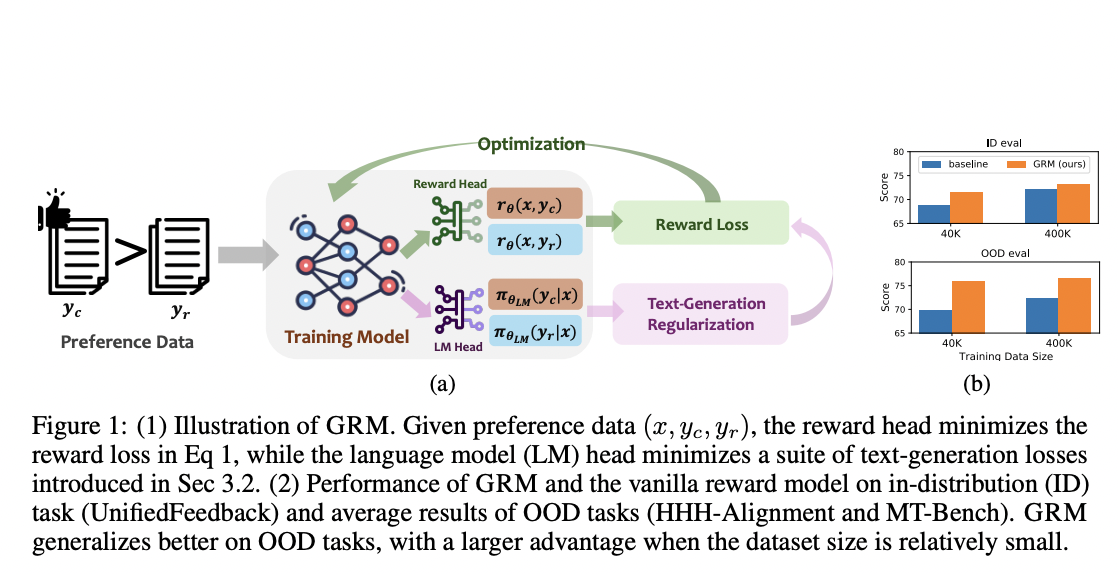
Исследователи из HKUST, Грузинского института технологий и Университета Иллинойса в Урбана-Шампейне представили Generalizable Reward Model (GRM), который использует регуляризацию генерации текста на скрытых состояниях для улучшения производительности моделей вознаграждения. Их исследование показывает, что все три типа регуляризации генерации текста хорошо работают с GRM, причем регуляризация SFT является наиболее эффективным и надежным решением. Результаты демонстрируют, что GRM значительно улучшает точность моделей вознаграждения в различных задачах вне распределения. Кроме того, он последовательно повышает производительность RLHF и помогает уменьшить проблему переоптимизации.
Заключение
В заключение, исследователи предложили Generalizable Reward Model (GRM) — эффективный метод, который направлен на улучшение обобщаемости и устойчивости обучения вознаграждения для LLM. GRM использует техники регуляризации на скрытых состояниях моделей вознаграждения, что значительно улучшает их обобщаемую производительность для невидимых данных. Кроме того, предложенный подход эффективно уменьшает проблему переоптимизации в RLHF. Эти результаты поддержат будущие исследования по созданию более сильных моделей вознаграждения, помогая эффективнее выстраивать большие модели и обеспечивать экономическую эффективность.
Проверьте статью. Вся кредит за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 46 тыс. подписчиков ML SubReddit.
Источник: MarkTechPost