
«`html
Ограничения существующих открытых многомодальных моделей (LMMs)
Существующие открытые большие многомодальные модели (LMMs) сталкиваются с несколькими значительными ограничениями. Они часто лишены интеграции и требуют адаптеров для выравнивания визуальных представлений с предварительно обученными большими языковыми моделями (LLMs). Многие LMMs ограничены одним модальным поколением или полагаются на отдельные модели диффузии для визуального моделирования и поколения. Эти ограничения вводят сложность и неэффективность как во время обучения, так и во время вывода. Существует потребность в по-настоящему открытой, авторегрессивной, многомодальной LMM, способной к генерации высококачественных, согласованных многомодальных последовательностей.
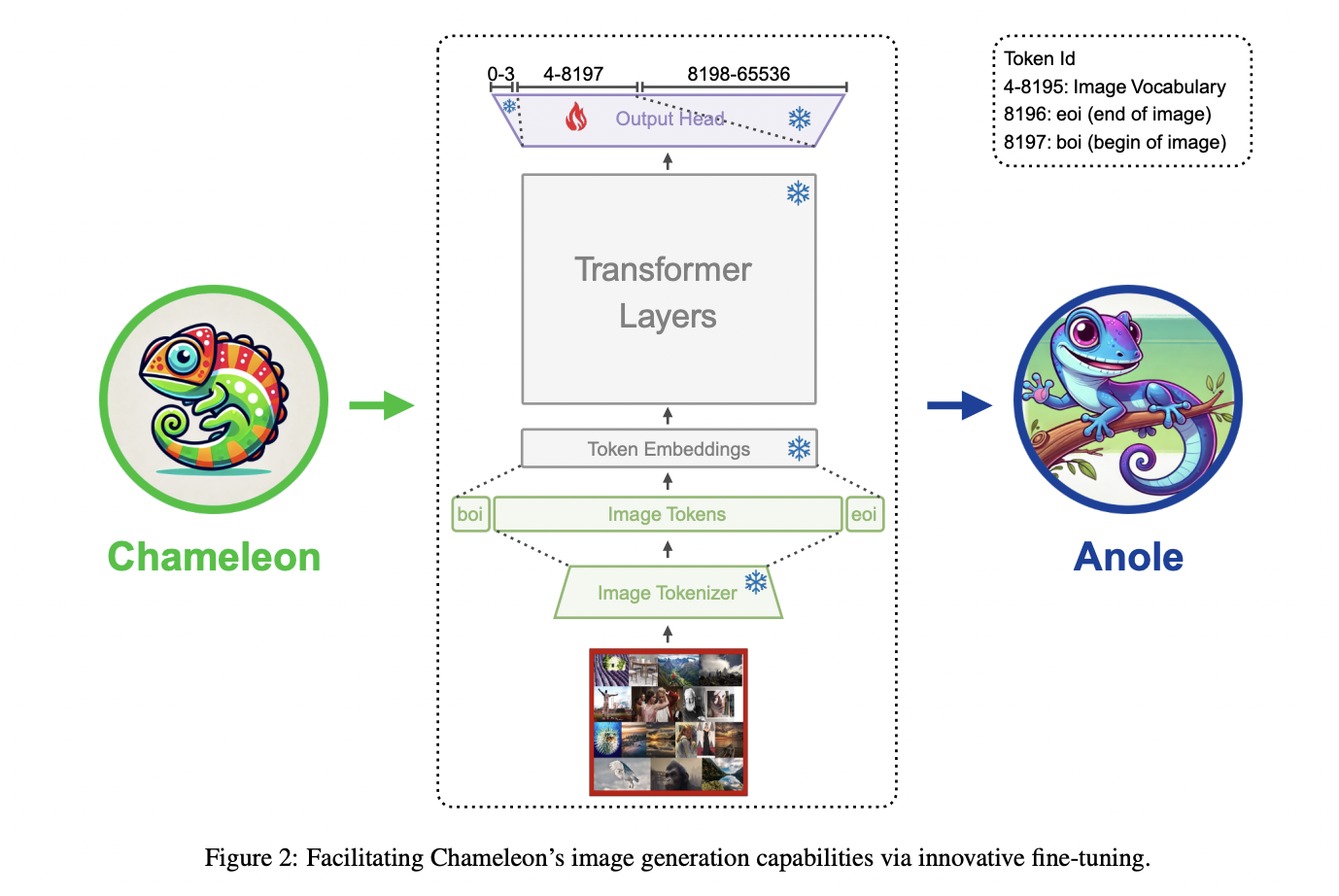
ANOLE: инновационное решение для многомодальной генерации
Исследователи из Generative AI Research Lab решают проблему ограниченных многомодальных функций в LMMs. Для решения этих проблем исследователи предлагают ANOLE, открытую, авторегрессивную, многомодальную LMM для переплетения генерации изображений и текста. Построенная на Chameleon Meta AI, ANOLE использует эффективную стратегию настройки и параметризации. Это позволяет обеспечить высококачественную многомодальную генерацию, используя ограниченные данные и параметры.
Преимущества ANOLE
ANOLE применяет подход раннего слияния на основе токенов для моделирования многомодальных последовательностей без использования моделей диффузии, полагаясь исключительно на трансформеры. Процесс настройки сосредотачивается на логитах, соответствующих идентификаторам токенов изображений в выходном слое головы трансформера. ANOLE-7b-v0.1 была разработана с использованием небольшого количества изображений (5859 изображений) и настроена на менее чем 40 млн параметров примерно за 30 минут на 8 A100 GPU.
Практическое применение ANOLE
ANOLE демонстрирует впечатляющие возможности генерации изображений и многомодальных последовательностей, производя высококачественные и согласованные переплетенные последовательности изображений и текста. Например, ANOLE способна генерировать детальные рецепты с соответствующими изображениями, а также создавать информативные переплетенные последовательности изображений и текста, такие как руководства по приготовлению традиционных китайских блюд или описания архитектурных проектов.
Заключение
Предложенный метод представляет собой значительный прогресс в области многомодального искусственного интеллекта, устраняя ограничения предыдущих открытых LMMs. ANOLE предлагает инновационное решение, которое является одновременно эффективным по данным и параметрам, обеспечивая высококачественные возможности многомодальной генерации. ANOLE демократизирует доступ к передовым технологиям многомодального искусственного интеллекта и укладывает дорогу для более инклюзивных и коллаборативных исследований в этой области.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу ML на Reddit.
«`




















