
«`html
Графовое обучение: решения для анализа и обработки графовых данных
Графовое обучение сосредотачивается на разработке передовых моделей, способных анализировать и обрабатывать реляционные данные, структурированные в виде графов. Это поле является важным в различных областях, включая социальные сети, академические сотрудничества, транспортные системы и биологические сети. По мере расширения реальных приложений графовых данных возрастает спрос на модели, способные эффективно обобщать различные графовые домены и обрабатывать врожденное разнообразие и сложность структур и особенностей графов. Решение этих проблем критически важно для раскрытия полного потенциала графовых исследований.
Проблемы графового обучения и их решения
Одной из значительных проблем в графовом обучении является разработка моделей, способных эффективно обобщать различные домены. Традиционные подходы часто нуждаются в помощи при работе с гетерогенностью графовых данных, которая включает вариации структурных свойств, представлений особенностей и сдвигов распределения между различными наборами данных. Эти вызовы ограничивают способность моделей быстро адаптироваться к новым, невидимым графам, снижая их применимость в реальных сценариях. Решение этих проблем критически важно для развития области и обеспечения широкого применения моделей графового обучения в различных доменах.
Существующие модели графового обучения, в частности, графовые нейронные сети (GNN), в последние годы сделали существенный прогресс. Однако эти модели часто ограничены своей зависимостью от обширной настройки и сложных процессов обучения. GNN обычно нуждаются в помощи при работе с разнообразными структурными и особенностными характеристиками реальных графовых данных. Это ограничение снижает их производительность и возможности обобщения, особенно при работе с задачами междоменного обучения, где данные графов существенно разнообразны. Эти вызовы требуют разработки более универсальных и адаптивных моделей.
AnyGraph: эффективная и эффективная модель графового обучения
Исследователи из Университета Гонконга представили AnyGraph, новую модель графового обучения, разработанную для преодоления вызовов гетерогенности графовых данных. AnyGraph построен на архитектуре Graph Mixture-of-Experts (MoE), что позволяет ему управлять сдвигами распределения внутри домена и между доменами в гетерогенности структуры и особенностей. Эта модель облегчает быструю адаптацию к новым графовым доменам, делая ее высокоуниверсальной и эффективной в обработке разнообразных графовых наборов данных. Используя архитектуру MoE, AnyGraph может динамически маршрутизировать входные графы к наиболее подходящей экспертной сети, оптимизируя свою производительность в различных типах графов.
Основная методология AnyGraph крутится вокруг его инновационного использования архитектуры Graph Mixture-of-Experts (MoE). Эта архитектура включает в себя несколько специализированных экспертных сетей, каждая из которых нацелена на захват конкретных структурных и особенностных характеристик графовых данных. Легкий механизм маршрутизации экспертов внутри AnyGraph позволяет модели быстро идентифицировать и активировать наиболее релевантных экспертов для данного входного графа, обеспечивая эффективную и точную обработку. В отличие от традиционных моделей, которые полагаются на одну фиксированную сеть, архитектура MoE AnyGraph позволяет ей динамически адаптироваться к тонкостям разнообразных графовых наборов данных. Более того, модель включает процесс унификации структуры и особенностей, где матрицы смежности и особенности узлов различных размеров отображаются в фиксированные векторные представления. Этот процесс улучшается с использованием сингулярного разложения (SVD) для извлечения особенностей, дополнительно улучшая способность модели обобщаться по различным графовым доменам.
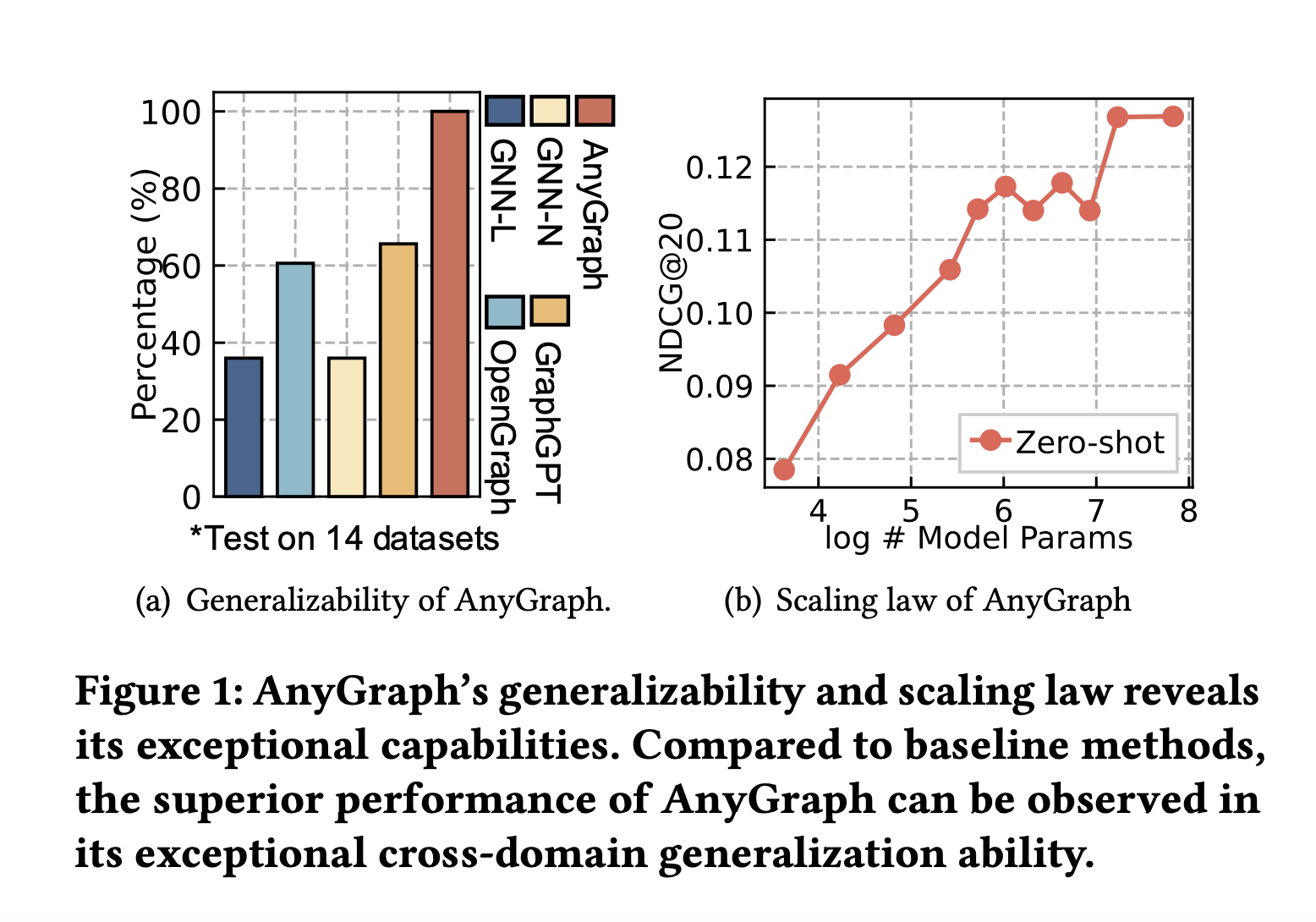
Производительность AnyGraph была тщательно оценена через обширные эксперименты на 38 разнообразных графовых наборах данных, охватывающих области, такие как электронная коммерция, академические сети, биологическая информация и другие. Результаты этих экспериментов подчеркивают превосходные возможности нулевого обучения AnyGraph, демонстрируя его способность эффективно обобщать различные графовые домены с существенными сдвигами распределения. Например, в наборах данных Link1 и Link2 AnyGraph достигал показателей recall@20 в размере 23,94 и 46,42 соответственно, значительно превосходя существующие модели. Более того, производительность AnyGraph следовала закону масштабирования, где точность модели улучшалась по мере увеличения размера модели и обучающих данных. Эта масштабируемость подчеркивает устойчивость и адаптивность модели, делая ее мощным инструментом для различных задач, связанных с графами. Более того, легкая природа механизма маршрутизации экспертов обеспечивает возможность AnyGraph быстро адаптироваться к новым наборам данных без необходимости обширной повторной тренировки, делая его практичным и эффективным решением для реальных приложений.
Заключение
Исследование, проведенное Университетом Гонконга, эффективно решает критические вызовы, связанные с гетерогенностью графовых данных. Введение модели AnyGraph представляет собой значительное развитие в графовом обучении, предлагая универсальное и надежное решение для обработки разнообразных графовых наборов данных. Инновационная архитектура MoE и динамический механизм маршрутизации экспертов позволяют ей эффективно обобщать различные домены, демонстрируя сильную производительность в задачах нулевого обучения. Масштабируемость и адаптивность AnyGraph дополнительно улучшают ее полезность, позиционируя ее как передовую модель в графовом обучении.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter и присоединиться к нашему каналу в Telegram и LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в Reddit.
Вот рекомендуемый вебинар от нашего спонсора: «Построение производительных приложений ИИ с помощью NVIDIA NIMs и Haystack».
Опубликовано на MarkTechPost.
«`



















