
«`html
PleIAs выпустил OCRonos-Vintage: Модель с 124 миллионами параметров, обученная на 18 миллиардах токенов для улучшения OCR в культурных архивах
PleIAs недавно объявил о выпуске OCRonos-Vintage, специализированной предварительно обученной модели, разработанной специально для коррекции оптического распознавания символов (OCR). Эта инновационная модель представляет собой значительный вех в технологии OCR, особенно в ее применении к архивам культурного наследия.
Технологический прорыв
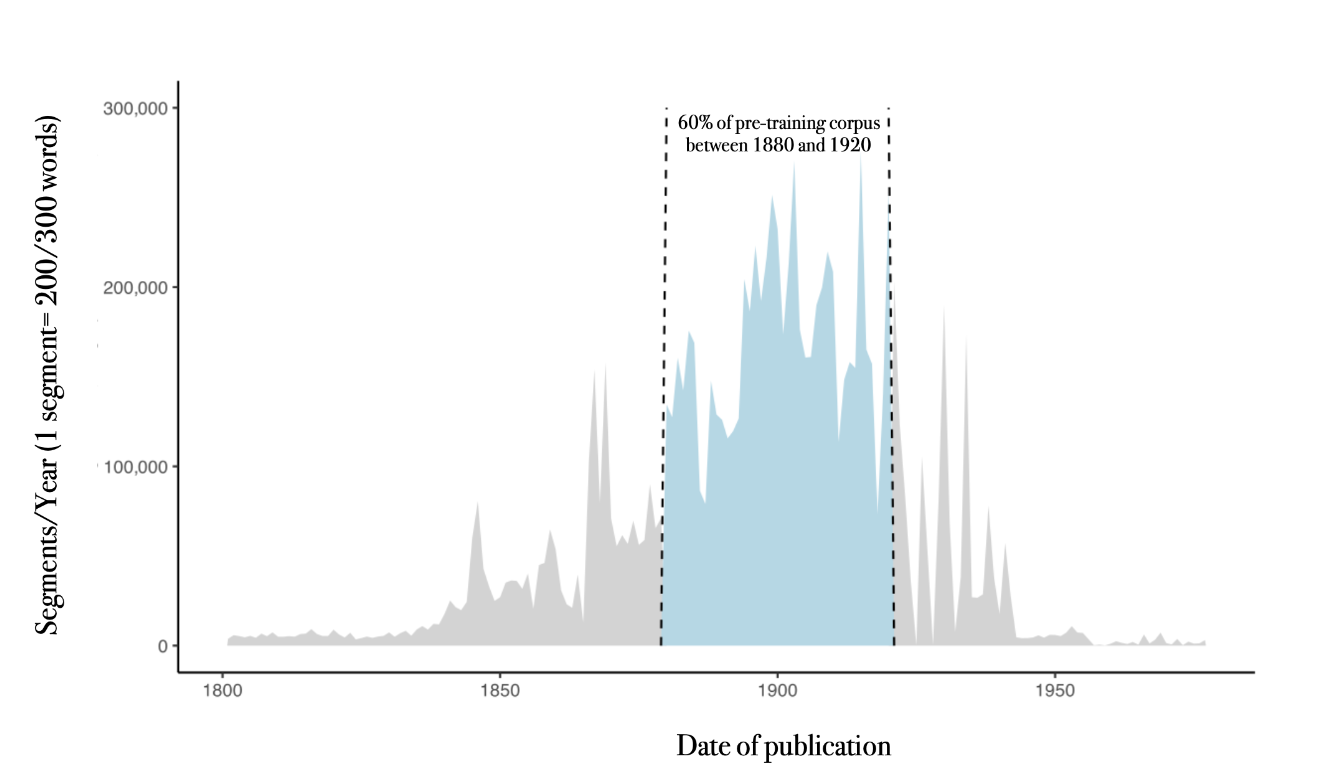
OCRonos-Vintage — это модель с 124 миллионами параметров, уникально обученная на 18 миллиардах токенов из архивов культурного наследия. Это специализированное обучение направлено на улучшение работы модели в исправлении ошибок OCR в исторических документах. OCRonos-Vintage продемонстрировал исключительную эффективность в этом узком приложении, несмотря на свой относительно небольшой размер по сравнению с другими моделями. Его разработка подчеркивает растущую тенденцию создания высокоспециализированных моделей, нацеленных на конкретные задачи, вместо полного полагания на большие, универсальные модели.
Практическое применение
Специализированное предварительное обучение, как в случае с OCRonos-Vintage, становится все более жизнеспособным и привлекательным по нескольким причинам. Одно из основных преимуществ — это экономия затрат. Модели с 100-300 миллионами параметров, подобные OCRonos-Vintage, могут быть развернуты на большинстве CPU инфраструктур без значительной адаптации или квантования. В среде GPU эти модели обеспечивают значительно более высокую производительность. Эффективность особенно важна для обработки больших объемов данных, таких как огромные архивы культурного наследия, на которые нацелен OCRonos-Vintage.
Другим важным преимуществом специализированного предварительного обучения является увеличение возможностей настройки. Архитектура и токенизатор модели могут быть специально разработаны с учетом целевой задачи и данных. Для коррекции OCR токенизатор, обученный на небольшой выборке шумных данных, может превзойти более общие модели. Этот подход позволяет оптимизировать модель для конкретных требований, таких как обработка длинных контекстов или улучшение понимания на не-английских языках. Потенциал для быстрого вывода и улучшенной производительности, даже на уровне токенизации букв или байтов, делает специализированные модели чрезвычайно адаптивными и эффективными.
Специализированное предварительное обучение предлагает полный контроль над используемыми данными. В регулируемых средах развертывание или доработка существующих моделей может вызывать опасения относительно ответственности за данные. Специализированные модели, подобные OCRonos-Vintage, обученные end-to-end на выбранных наборах данных, избегают этих проблем. Все обучающие данные для OCRonos-Vintage поступают из архивов культурного наследия общественного достояния, обеспечивая соответствие требованиям использования данных и способствуя прозрачности.
Заключение
Запуск OCRonos-Vintage от PleIAs является значительным событием в развитии специализированных моделей искусственного интеллекта. Сосредотачиваясь на конкретных задачах и оптимизации моделей, PleIAs демонстрирует, что специализированное предварительное обучение может обеспечить исключительную производительность, сохраняя при этом эффективность и экономичность. Этот подход продвигает область коррекции OCR и устанавливает прецедент для разработки специализированных моделей искусственного интеллекта в различных областях.
Проверьте модель и подробности. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Найдите предстоящие вебинары по ИИ здесь.
«`



















