
«`html
Решение проблемы токсичности в многоязычных моделях языка
Проблема
Рост некачественных данных в Интернете приводит к возникновению вредных или токсичных знаний в больших языковых моделях (LLM). При использовании этих моделей в чат-ботах растет риск выставления пользователей на вредные советы или агрессивное поведение.
Решение
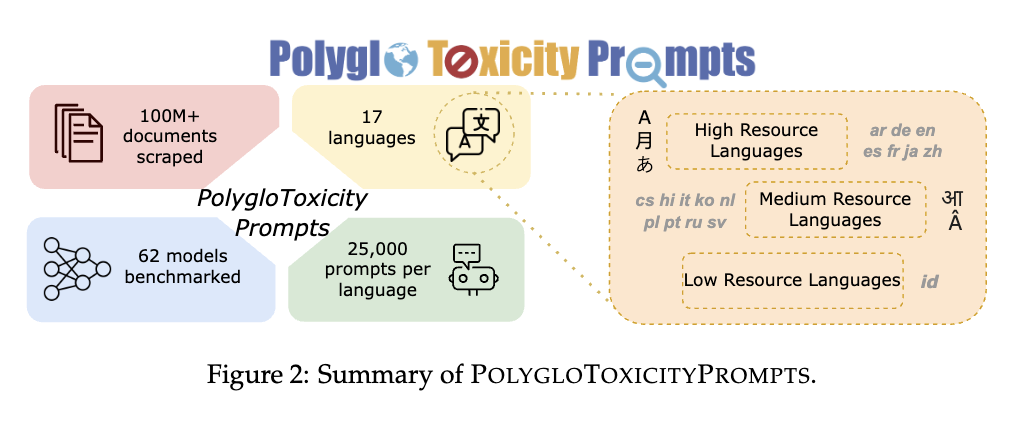
AI2 в сотрудничестве с CMU решает задачу ограничения токсичности в многоязычных LLM. Для этого был разработан датасет PolygloToxicityPrompts, состоящий из 425 000 естественных запросов на 17 языках с различной степенью токсичности. Этот датасет предназначен для более точного представления токсичности в LLM за счет фокуса на короткие потенциально токсичные текстовые фрагменты.
Используя PerspectiveAPI для измерения токсичности запросов и генераций, исследователи определили, что современные многоязычные LLM проявляют наивысшие уровни токсичности в языках с меньшим количеством доступных данных высокого качества, таких как хинди и чешский, и наименьшие — в языках, таких как русский и голландский.
Исследование также учитывает влияние размера модели и методов выравнивания на токсичность. Оно показывает, что для базовых LLM токсичность увеличивается с размером модели, однако модели, настроенные на инструкции и предпочтения, менее токсичны.
Заключение
Датасет PolygloToxicityPrompts представляет ценный инструмент для оценки и смягчения токсичности в многоязычных LLM. Исследование выделяет важность языка запросов, размера модели и методов выравнивания для борьбы с токсичностью. Датасет содействует созданию более надежных моделей для проактивной модерации и фильтрации многоязычного контента, способствуя безопасной онлайн-среде.
Подробнее о статье и датасете вы можете узнать [здесь](https://example.com).
«`




















