
«`html
Синтетический набор данных GSM8K-Reflection-405B открыт для использования
С использованием искусственного интеллекта растет потребность в высококачественных наборах данных, которые могут поддерживать обучение и оценку моделей в различных областях. Одним из значительных событий стало общедоступное распространение набора данных Synthetic-GSM8K-reflection-405B от Gretel.ai, который обладает значительным потенциалом для выполнения задач рассуждения, особенно тех, которые требуют многошагового решения проблем. Этот недавно выпущенный набор данных, размещенный на платформе Hugging Face, был синтетически сгенерирован с использованием инструмента Gretel Navigator, при этом в качестве языковой модели агента (LLM) использовалась Meta-Llama-3.1-405B. Его создание отражает достижения в области использования синтетически генерируемых данных и отражения искусственного интеллекта для разработки надежных моделей ИИ.
Создание синтетических данных с использованием техник отражения
Одной из выдающихся особенностей набора данных Synthetic-GSM8K-reflection-405B является его использование синтетически генерируемых данных. Синтетически созданные, а не собранные из реальных событий, синтетические данные все более важны для обучения моделей ИИ. В данном случае набор данных был создан с использованием инструмента Gretel Navigator, сложного средства генерации синтетических данных. Этот уникальный набор данных использует Meta-Llama-3.1-405B, передовую LLM, в качестве генерирующего агента.
Разнообразные контексты реального мира и тщательная проверка
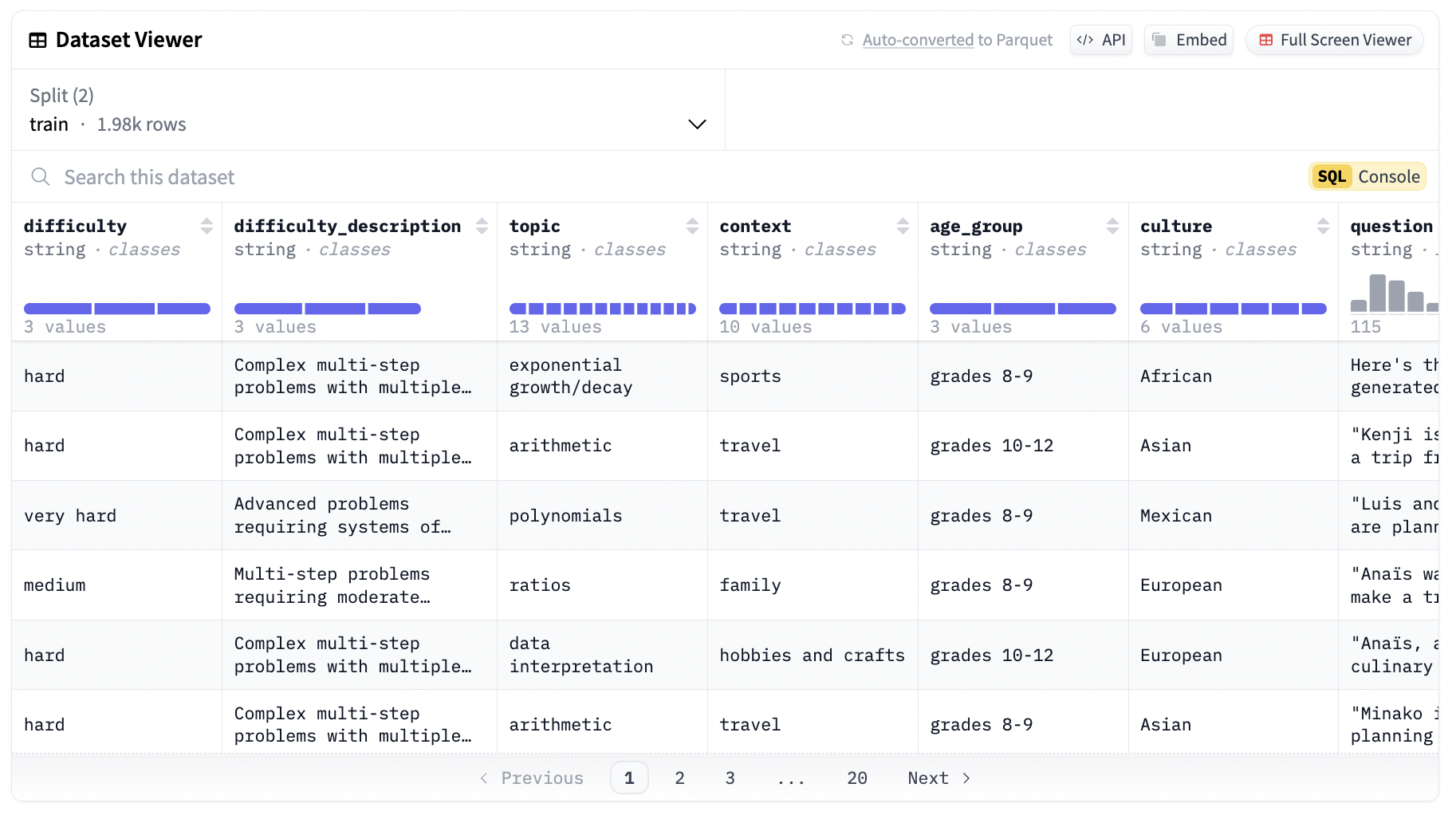
Еще одной ключевой особенностью набора данных Synthetic-GSM8K-reflection-405B является разнообразие его вопросов. Дизайн набора данных обеспечивает стратификацию проблем по сложности и теме, охватывая широкий спектр контекстов реального мира. Это разнообразие делает набор данных очень универсальным и применимым в различных областях, от академических задач до индустриальных сценариев, требующих надежных навыков решения проблем.
Обучающие и тестовые наборы для разработки моделей
Набор данных Synthetic-GSM8K-reflection-405B тщательно разработан для поддержки развития моделей ИИ. Он поставляется как с обучающими, так и тестовыми наборами, содержащими в общей сложности 300 примеров, разделенных по уровням сложности: средним, сложным и очень сложным. Это разделение важно для оценки моделей. Предоставляя отдельные наборы для обучения и тестирования, набор данных позволяет разработчикам обучать модели на одной части данных и оценивать их производительность на другой части. Это помогает оценить, насколько хорошо модель обобщается на невидимые данные, ключевой показатель ее надежности и эффективности.
Потенциальные применения и влияние
Открытое распространение набора данных Synthetic-GSM8K-reflection-405B от Gretel.ai обещает значительное влияние на сообщество искусственного интеллекта и машинного обучения. Его акцент на задачах рассуждения делает его идеальным набором данных для разработки моделей, требующих способностей к многошаговому решению проблем. Эти модели могут применяться во многих областях, таких как образование, где ИИ может помочь в решении сложных математических задач, или в отраслях, таких как финансы и инженерия, где многошаговое рассуждение играет решающую роль в процессах принятия решений.
Роль Hugging Face в демократизации искусственного интеллекта
Открытое распространение набора данных Synthetic-GSM8K-reflection-405B на платформе Hugging Face еще один шаг в направлении демократизации искусственного интеллекта. Hugging Face стал центральным хабом для разработчиков и исследователей в области ИИ, предлагая доступ к множеству моделей и наборов данных. Сделав этот набор данных бесплатно доступным, Gretel.ai вносит свой вклад в коллективный характер развития ИИ, где исследователи и разработчики по всему миру могут получить доступ к существующим ресурсам и строить на их основе.