
«`html
Sarvam AI представил новую языковую модель Sarvam-2B
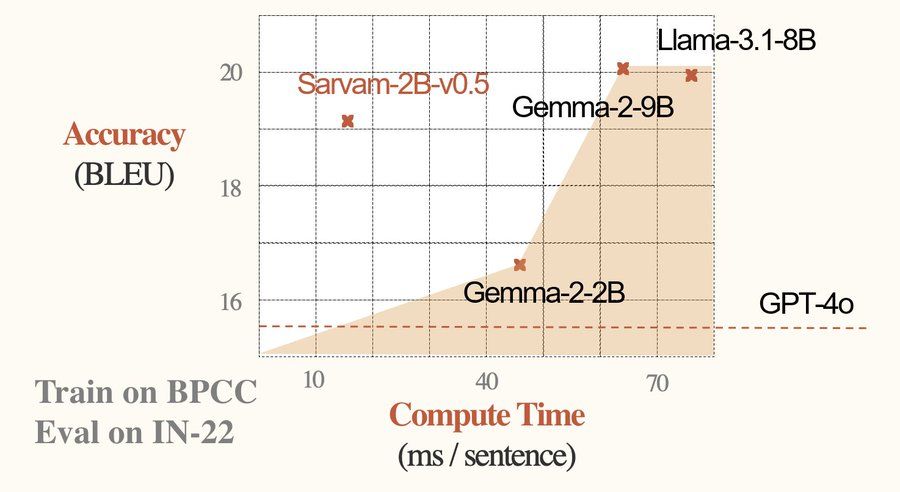
Sarvam AI недавно представила свою передовую языковую модель Sarvam-2B. Эта мощная модель, обладающая 2 миллиардами параметров, представляет собой значительное совершенствование в обработке индийских языков. Она предварительно обучена с нуля на массивном наборе данных из 4 триллионов высококачественных токенов, при этом порядка 50% посвящены индийским языкам. Это развитие, особенно их способность понимать и генерировать текст на языках, исторически недостаточно исследовались в области ИИ.
Набор данных Samvaad-Hi-v1 и его значение
Кроме того, был представлен набор данных Samvaad-Hi-v1 — тщательно отобранный набор из 100 000 качественных английских, хинди и хинглиш разговоров. Этот набор данных уникально спроектирован с индийским контекстом, что делает его бесценным ресурсом для исследователей и разработчиков, работающих над мультиязычными и культурно значимыми моделями ИИ. Samvaad-Hi-v1 призван улучшить обучение разговорных систем ИИ, способных понимать и взаимодействовать с пользователями более естественно и контекстно соответственно различным языкам и диалектам, характерным для Индии.
Видение Sarvam-2B
Визия Sarvam AI с Sarvam-2B ясна: создать мощную и универсальную языковую модель, которая выделяется в английском и поддерживает индийские языки.
Техническое совершенство и внедрение
Sarvam-2B была обучена на сбалансированной смеси данных на английском и индийских языках, при этом внимание было уделено тому, что каждый язык внес равный вклад в обучение. Этот тщательный баланс гарантирует, что модель одинаково виртуозна как в английском, так и в поддерживаемых индийских языках. Процесс обучения включал сложные техники для улучшения понимания и генерации моделью, делая ее одной из самых передовых в своей категории.
Расширение возможностей и комплементарные модели
Помимо Sarvam-2B, Sarvam AI также представила три других выдающихся модели, дополняющих ее возможности:
Bulbul 1.0: модель преобразования текста в речь (TTS), поддерживающая сочетания 10 языков и шесть голосов. Эта модель генерирует звучащую естественную речь, делая ее ценным инструментом для приложений, требующих многоязычного звукового вывода.
Saaras 1.0: модель речи в текст (STT), поддерживающая те же десять языков и включающая автоматическую идентификацию языка. Эта модель особенно полезна для транскрибирования устной речи в текст, с дополнительным преимуществом автоматического определения языка.
Mayura 1.0: API для перевода, разработанный для обработки сложностей перевода между индийскими языками и английским языком. Эта модель адаптирована для решения тонких моментов и уникальных проблем, связанных с индийскими языками, обеспечивая более точные и культурно значимые переводы.
Вывод
Sarvam AI запустила Sarvam-2B, особенно в контексте языковых моделей, предназначенных для индийских языков. Благодаря тому, что половина ее учебных данных посвящена этим языкам, Sarvam-2B выделяется как модель, активно пропагандирующая важность языкового разнообразия. Универсальность модели, совместно с дополнительными возможностями Bulbul 1.0, Saaras 1.0 и Mayura 1.0, позиционирует Sarvam AI как лидера в области разработки инклюзивных, инновационных и перспективных технологий ИИ.
Подробнее о моделе и наборе данных можно узнать на сайте компании.
Вся благодарность за этот исследовательский проект исследователям этого проекта.
Не забудьте следить за нашими новостями в Twitter и присоединиться к нашей группе в LinkedIn. Если вам нравится наша работа, вам понравится наша подписка.
Не забудьте присоединиться к нашему сообществу на Reddit!
Вы можете найти предстоящие вебинары по ИИ здесь.
Arcee AI выпустила DistillKit: открытый и простой в использовании инструмент для трансформации моделей для создания эффективных, высокопроизводительных небольших языковых моделей
«`





















