
«`html
Мультимодальные модели больших языков (MLLM) и их значение для анализа данных
Мультимодальные модели больших языков (MLLM) активно интегрируют в себя обработку естественного языка (NLP) и компьютерное зрение, что является важным для анализа визуальных и текстовых данных. Они особенно ценны для интерпретации сложных графиков в научных статьях, финансовых отчетах и других документах.
Проблемы и практические решения
Одной из основных проблем является необходимость улучшения способности этих моделей понимать и интерпретировать такие графики. Однако текущие бенчмарки часто нуждаются в большей точности для обоснования этой задачи, что приводит к переоценке возможностей MLLM. Проблема заключается в отсутствии разнообразных и реалистичных наборов данных, отражающих реальные сценарии, что критически важно для оценки реальной производительности этих моделей.
Существует значительная проблема в исследованиях MLLM в виде слишком упрощенных существующих бенчмарков. Наборы данных, такие как FigureQA, DVQA и ChartQA, основаны на процедурно генерируемых вопросах и графиках, которые нуждаются в большей визуальной разнообразности и сложности. Эти бенчмарки должны отражать сложности реальных графиков, поскольку они используют вопросы на основе шаблонов и однородные дизайны графиков. Это ограничение приводит к неточной оценке способностей модели в понимании графиков, поскольку бенчмарки должны должным образом вызывать вызовы для моделей.
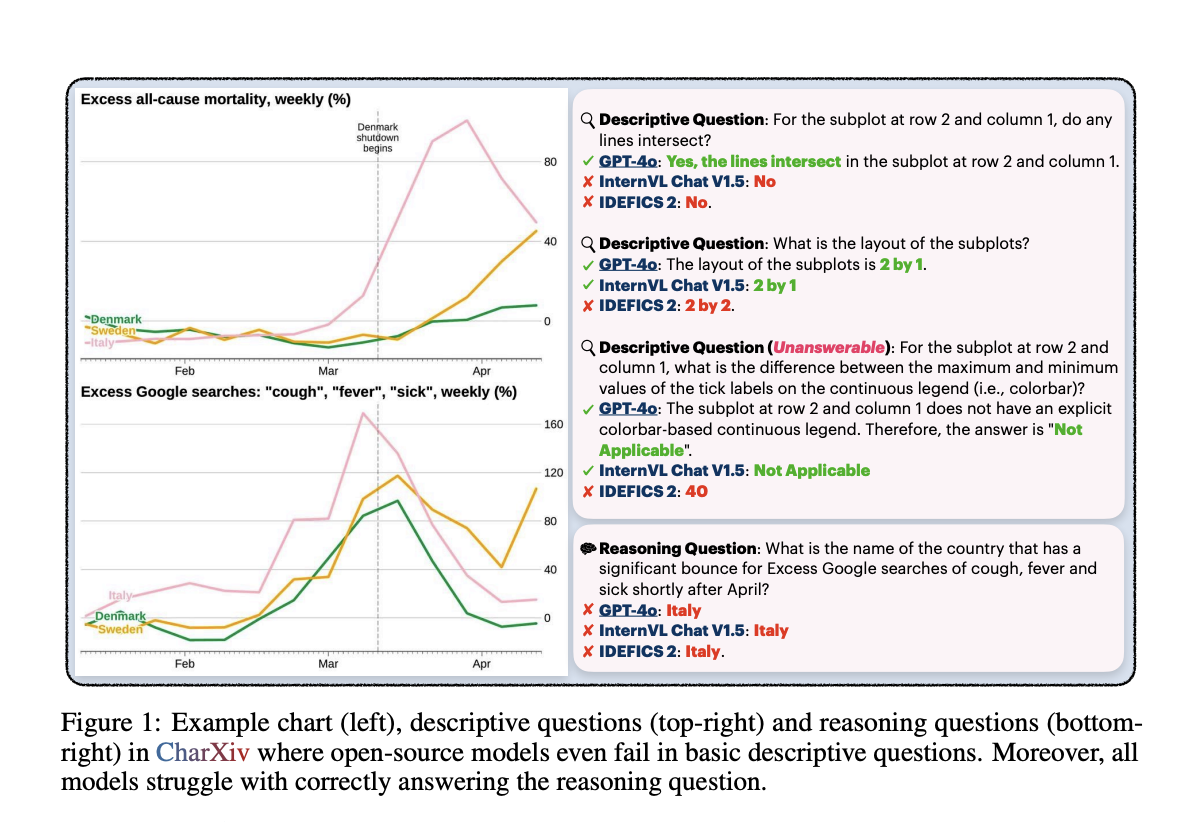
Исследователи из Университета Принстон, Университета Висконсина и Университета Гонконга представили CharXiv — комплексный набор для оценки, созданный для предоставления более реалистичной и сложной оценки производительности MLLM. CharXiv включает 2 323 графика из статей arXiv, охватывающих различные предметы и типы графиков. Эти графики сопровождаются описательными и рассудительными вопросами, требующими детального визуального и числового анализа. Набор данных охватывает восемь основных академических предметов и содержит разнообразные и сложные графики для тщательного тестирования способностей моделей.
Преимущества CharXiv и результаты исследования
CharXiv выделяется своим тщательно отобранными вопросами и графиками, предназначенными для оценки описательных и рассудительных способностей MLLM. Описательные вопросы фокусируются на основных элементах графика, таких как заголовки, метки и деления, в то время как рассудительные вопросы требуют синтеза сложной визуальной информации и числовых данных. Все графики и вопросы были тщательно подобраны, отобраны и проверены экспертами, чтобы обеспечить высокое качество и актуальность. Этот тщательный процесс курации направлен на создание реалистичного бенчмарка, более эффективно вызывающего вызовы для MLLM по сравнению с существующими наборами данных, что в конечном итоге приводит к улучшению производительности и надежности моделей в практических приложениях.
В результате исследования CharXiv были проведены обширные тесты на 13 открытых и 11 закрытых моделях, выявив значительный разрыв в производительности. Сильнейшая закрытая модель, GPT-4o, достигла 47,1% точности на рассудительных вопросах и 84,5% на описательных вопросах. В то время как ведущая открытая модель, InternVL Chat V1.5, показала только 29,2% точности на рассудительных вопросах и 58,5% на описательных. Эти результаты подчеркивают вызовы, с которыми сталкиваются текущие MLLM в понимании графиков, поскольку производительность человека на этих задачах была значительно выше, с 80,5% точности на рассудительных вопросах и 92,1% на описательных вопросах. Этот разрыв в производительности подчеркивает необходимость более надежных и вызывающих вызовы бенчмарков, подобных CharXiv, для дальнейших прорывов в этой области.
Заключение и практическое применение
Результаты исследования CharXiv предоставляют важные инсайты в сильные и слабые стороны текущих MLLM. Например, разрыв в производительности между закрытыми и открытыми моделями показывает, что первые лучше приспособлены к обработке сложности и разнообразия реальных графиков. Оценка показала, что описательные навыки являются предпосылкой для эффективного рассуждения, поскольку модели с сильными описательными способностями имеют тенденцию лучше справляться с рассудительными задачами. Модели также нуждаются в помощи в композиционных задачах, таких как подсчет меток на осях, которые являются простыми для людей, но вызывают трудности для MLLM.
В заключение, CharXiv решает критические недостатки существующих бенчмарков. Предоставляя более реалистичный и вызывающий вызовы набор данных, CharXiv позволяет более точно оценить производительность MLLM в интерпретации сложных графиков. Выявленные значительные разрывы в производительности подчеркивают необходимость дальнейших исследований и улучшений. Комплексный подход CharXiv направлен на стимулирование будущих прорывов в способностях MLLM, что в конечном итоге приведет к более надежным и эффективным моделям для практических применений.
Проверьте статью и проект. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу более чем 45 тыс. участников в ML SubReddit.
Попробуйте AI Sales Bot https://itinai.ru/aisales Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai . Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
«`



















