
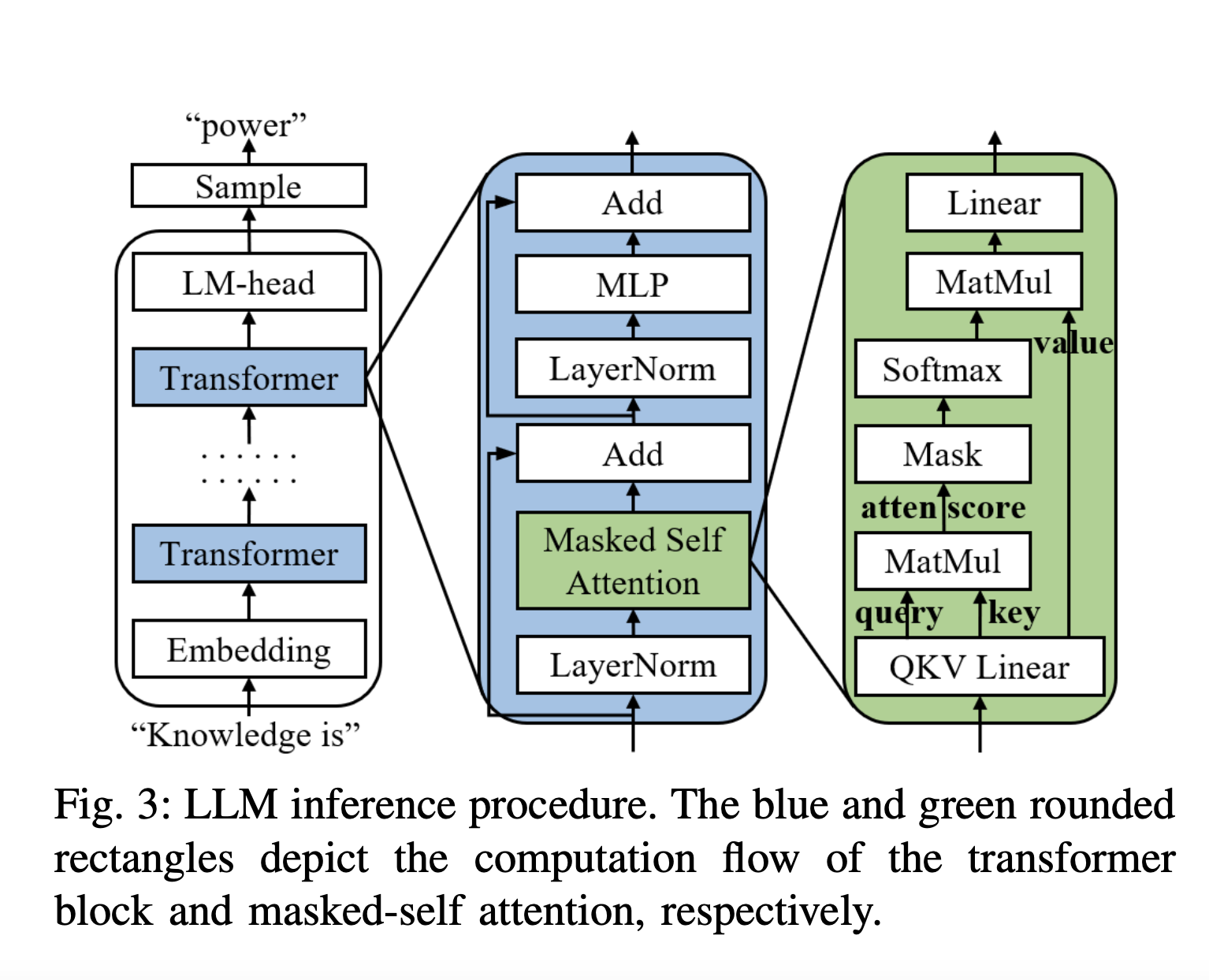
«`html
Преимущества применения Transformer-моделей в обработке естественного языка
Transformer-модели показали свою эффективность в широком спектре задач обработки естественного языка (NLP). Множество приложений могут использовать эти модели, однако их тренировка и реализация часто являются затратными для разработчиков.
AI-сервисы для доступа к языковым моделям
Крупные компании, такие как OpenAI, Google и Baidu, предлагают сервис языковых моделей (LMaaS) через API для облегчения доступа к своим LLM.
Проблемы в обработке запросов
Существующие системы, такие как TensorFlow Serving и Triton Inference Server, имеют неэффективности в обработке запросов, используя ограниченные пакеты, что ограничивает параллельные вычисления на GPU.
Решение — Magnus
Команда исследователей из Китая предложила систему Magnus, которая использует семантическую информацию на уровне приложения и пользователя для прогнозирования длины запросов. Magnus позволяет оптимизировать обработку запросов на языковые модели, значительно увеличивая производительность и снижая время ответа.
Результаты тестирования
Тестирование прототипа системы Magnus на графических процессорах NVIDIA V100 показало улучшение пропускной способности запросов и сокращение времени ответа по сравнению с базовыми подходами.
Подробнее о проекте
Для ознакомления с исследованием ознакомьтесь с Paper.
«`



















