
Инновационное решение для оптимизации памяти в больших языковых моделях
Проблема:
Большие языковые модели (LLM) требуют большого объема памяти для обработки длинных текстов, что затрудняет их применение на различных устройствах.
Решение:
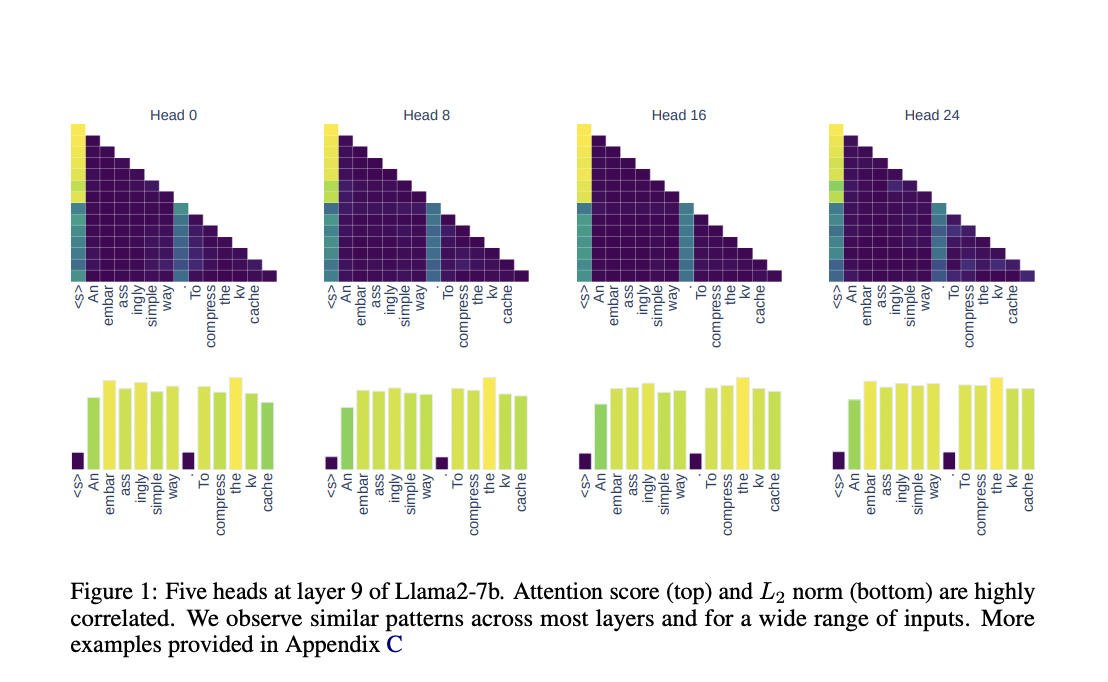
Исследователи из Университета Эдинбурга и Университета Сапиенца предложили метод сжатия кэша ключ-значение (KV), основанный на норме L2, что позволяет сократить использование памяти до 50% без потери точности модели.
Практическое применение:
Этот подход позволяет эффективно управлять памятью в LLM, не требуя сложных алгоритмов или дополнительных ресурсов. Результаты показывают сохранение высокой точности модели при существенном сокращении потребления памяти.
Значимость:
Использование данного метода позволяет расширить применение LLM в различных отраслях и задачах, где требуется обработка больших объемов данных и длительных текстов.
Контакты:
Хотите узнать больше о внедрении ИИ в ваш бизнес? Пишите нам на Telegram или следите за новостями в Telegram-канале и Twitter.
Дополнительные ресурсы:
Испытайте AI Sales Bot здесь и узнайте, как решения от AI Lab itinai.ru могут изменить ваши бизнес-процессы.


















