
«`html
Представляем Инженерию Вывода Predibase
Predibase анонсирует свою новую инфраструктуру — Инженерия Вывода Predibase, которая предназначена для эффективного развертывания настроенных моделей маленького языка (SLMs). Это решение значительно ускоряет работу с SLM, делая его более масштабируемым и экономичным для предприятий.
Проблемы развёртывания AI
При внедрении AI компании сталкиваются с несколькими ключевыми проблемами:
- Проблемы с производительностью: Стандартные облачные GPU часто не справляются с высокими нагрузками, что приводит к медленным ответам.
- Сложность инженерии: Использование моделей с открытым исходным кодом требует значительных ресурсов на поддержание инфраструктуры.
- Высокие затраты на инфраструктуру: Дорогие модели GPU часто доступны в ограниченном количестве, что создает дефицит.
Практические решения Инженерии Вывода
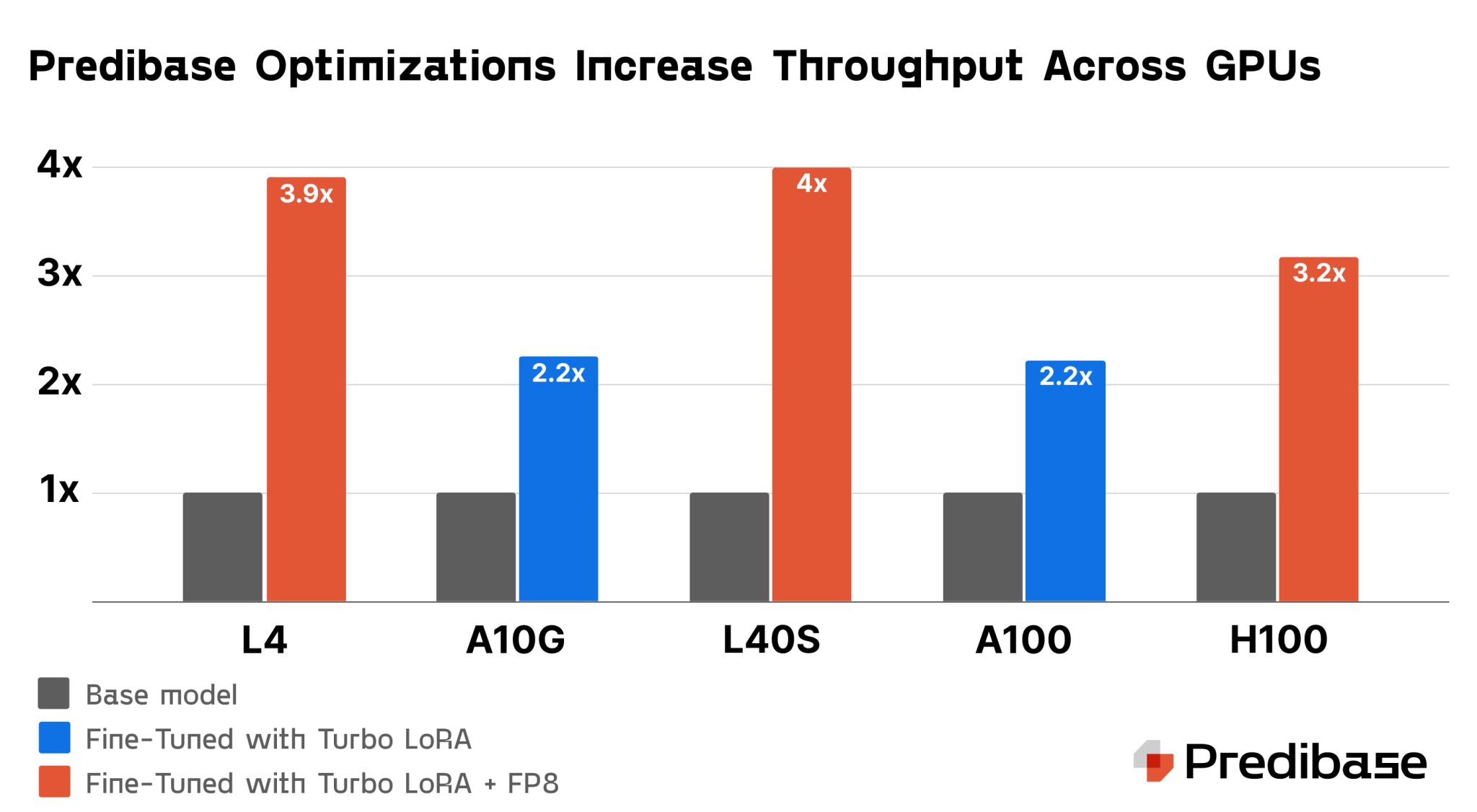
- LoRAX: Позволяет обслуживать сотни SLM с одного GPU, что существенно снижает затраты.
- Turbo LoRA: Увеличивает скорость обработки на 2-3 раза, сохраняя высокое качество ответов.
- FP8 Квантование: Снижает использование памяти на 50%, улучшая производительность и уменьшая затраты.
- Автоскейлинг GPU: Динамически настраивает ресурсы в зависимости от текущих потребностей, снижая расходы.
Надежность и готовность к бизнесу
Инженерия Вывода Predibase предлагает решения, готовые к использованию на уровне предприятий, включая интеграцию с VPC, многоуровневую доступность и аналитические инструменты для мониторинга.
Преимущества выбора Predibase
Predibase — это ведущая платформа для работы с настроенными SLM, предлагающая надежную инфраструктуру, соответствующую современным стандартам. Если вы готовы улучшить свои модели LLM, свяжитесь с нами, чтобы узнать больше о Инженерии Вывода Predibase.
«`




















