
«`html
Новые исследования из Стэнфордского университета раскрывают проблему коллапса модели ИИ и накопления данных
Большие генеративные модели, такие как GPT-4, DALL-E и Stable Diffusion, продемонстрировали удивительные возможности в генерации текста, изображений и других медиа, трансформируя искусственный интеллект. Однако с увеличением распространенности этих моделей возникает критическое вызов — последствия обучения генеративных моделей на наборах данных, содержащих их результаты. Эта проблема, известная как коллапс модели, представляет существенную угрозу будущему развитию ИИ. По мере того, как генеративные модели обучаются на веб-масштабных наборах данных, включающих все больше контента, созданного ИИ, исследователи сталкиваются с потенциальным ухудшением производительности модели на последующих итерациях, что может сделать новые модели неэффективными и подорвать качество обучающих данных для будущих систем ИИ.
Практические решения:
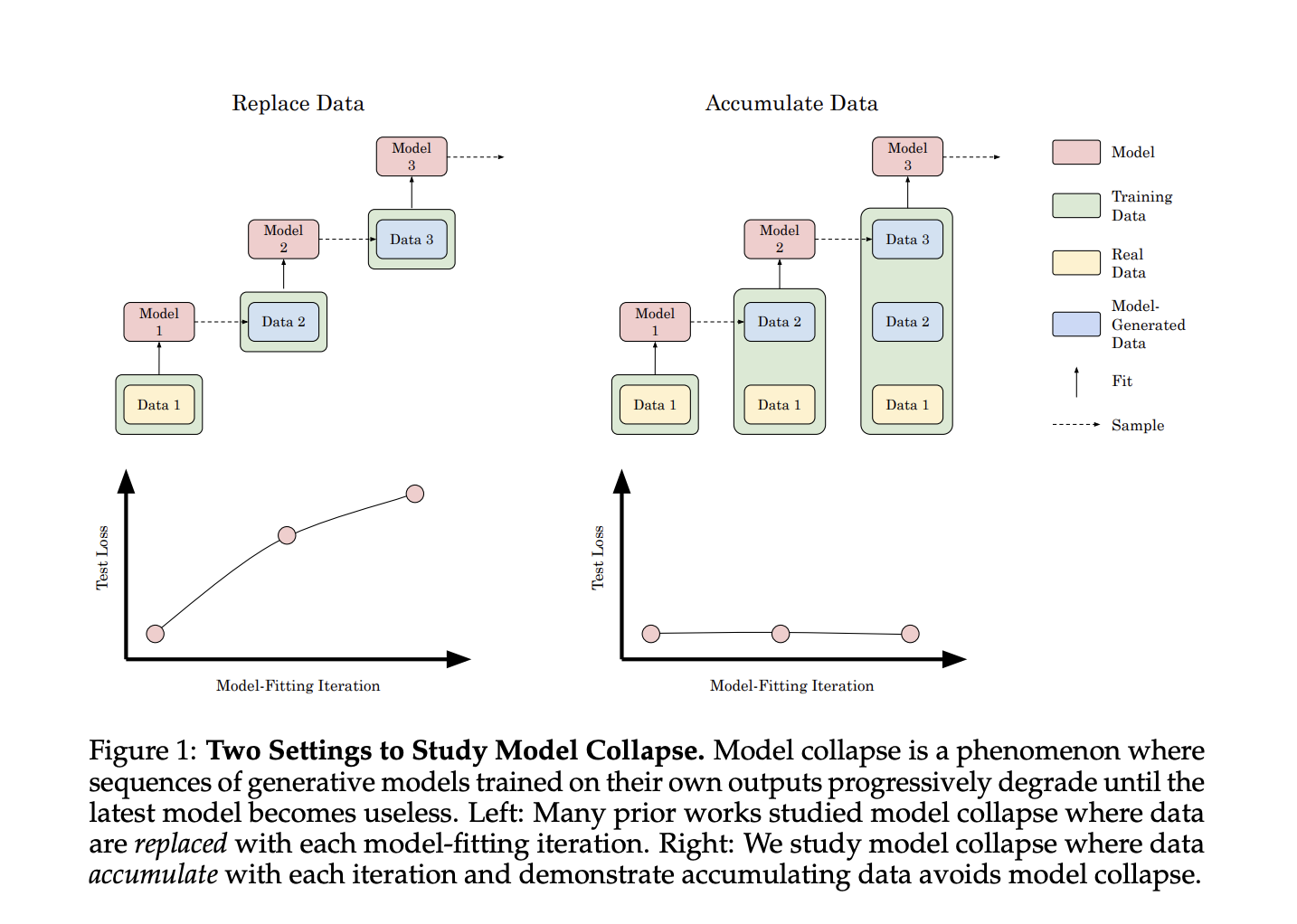
Исследователи из Стэнфордского университета предлагают исследование, которое исследует влияние накопления данных на коллапс модели в генеративных моделях ИИ. В отличие от предыдущих исследований, сосредоточенных на замене данных, этот подход имитирует непрерывное накопление синтетических данных в интернет-основанных наборах данных. Эксперименты с трансформаторами, моделями диффузии и вариационными автокодировщиками различных типов данных показывают, что накопление синтетических данных вместе с реальными данными предотвращает коллапс модели, в отличие от наблюдаемого ухудшения производительности при замене данных.
Применение в различных областях ИИ:
Исследователи экспериментально исследовали коллапс модели в генеративном ИИ, используя причинные трансформаторы, модели диффузии и вариационные автокодировщики в текстовых, молекулярных и изображенческих наборах данных.
Заключение:
Это исследование расследует проблему коллапса модели в ИИ, озабоченность появлением контента, созданного ИИ, в обучающих наборах данных. В отличие от предыдущих исследований, показавших, что обучение на выходах модели может ухудшить производительность, данная работа демонстрирует, что коллапс модели может быть предотвращен обучением на смеси реальных и синтетических данных.
Подробнее о работе можно узнать в этой статье. Все права на исследование принадлежат его авторам.
Также не забудьте подписаться на наш Twitter и присоединиться к нашей группе в LinkedIn. Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему SubReddit по машинному обучению и нейронным сетям.
Также вы можете найти информацию о предстоящих вебинарах по ИИ здесь.
Источник: MarkTechPost
«`



















