LLMs могут обучаться без меток
Исследователи из Университета Цинхуа и Шанхайской лаборатории ИИ представили метод обучения с подкреплением во время тестирования (TTRL), который позволяет языковым моделям самостоятельно эволюционировать, используя немаркированные данные.
Проблема зависимости от размеченных данных
Несмотря на значительные достижения в области логического мышления с помощью обучения с подкреплением (RL), большинство крупных языковых моделей (LLMs) по-прежнему зависят от размеченных данных. Методы, такие как RLHF, улучшили производительность моделей, но требуют человеческой обратной связи и размеченных наборов данных. В условиях динамичной среды, где LLMs применяются в образовании и научных исследованиях, необходимо обобщение за пределами подготовленных данных.
Метод TTRL: использование приоритетов модели для самонастройки
TTRL представляет собой обучающую структуру, которая применяет RL во время тестирования, используя только немаркированные тестовые данные. Метод использует внутренние приоритеты предобученных языковых моделей для оценки псевдонаград через голосование по большинству среди сгенерированных ответов.
Этапы TTRL
- Оценка меток через голосование: Для каждого запроса модель генерирует несколько ответов, и наиболее частый ответ принимается за оцененную метку.
- Назначение наград и оптимизация политики: Каждому сгенерированному ответу присваивается бинарная награда в зависимости от соответствия оцененной метке. Модель обновляется с использованием алгоритмов RL для максимизации согласия с псевдонаградами.
Эмпирические результаты
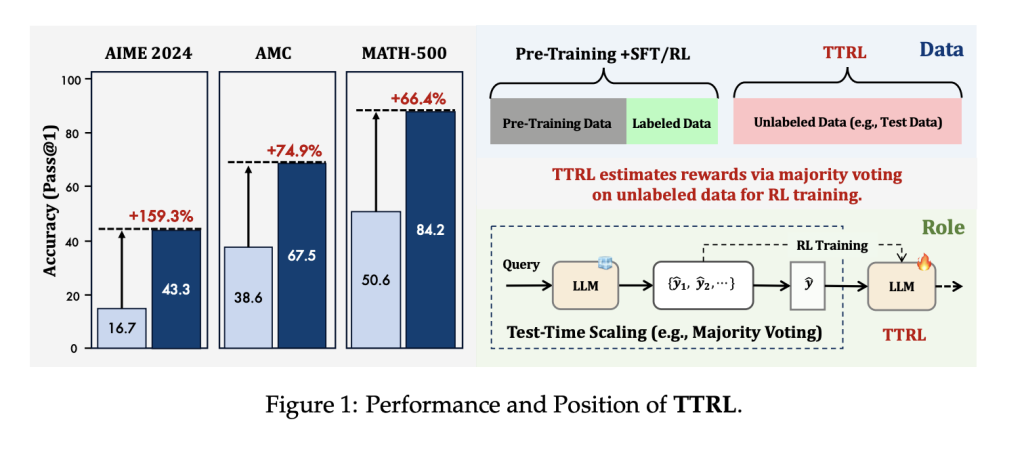
TTRL был протестирован на трех математических задачах: AIME 2024, AMC и MATH-500. Результаты показывают значительное улучшение производительности:
- Для модели Qwen2.5-Math-7B производительность на AIME 2024 увеличилась с 16.7% до 43.3% (pass@1), что составляет прирост на 159.3% без использования размеченных данных.
- В среднем, по трем задачам, модель достигла относительного прироста в 84.1%.
- Модель Qwen2.5-Math-1.5B улучшила свои результаты с 33.0% до 80.0% на MATH-500.
Заключение: к самонастраивающемуся и безметочному обучению
TTRL представляет собой новый подход к применению обучения с подкреплением для LLM в реальных условиях. Используя собственные генерации модели в качестве прокси для супервизии, TTRL устраняет необходимость в дорогих человеческих аннотациях и позволяет непрерывную адаптацию. Этот метод хорошо масштабируется и совместим с различными алгоритмами RL.
Практические рекомендации для бизнеса
Рассмотрите возможность автоматизации процессов, где ИИ может добавить наибольшую ценность. Определите ключевые показатели эффективности (KPI), чтобы убедиться, что ваши инвестиции в ИИ приносят положительный результат. Выберите инструменты, которые соответствуют вашим потребностям и позволяют настраивать их под ваши цели. Начните с небольшого проекта, соберите данные о его эффективности и постепенно расширяйте использование ИИ в вашей работе.
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram.
Пример решения на основе ИИ
Посмотрите на практический пример решения на основе ИИ: бот для продаж от itinai.ru, который предназначен для автоматизации общения с клиентами круглосуточно и управления взаимодействиями на всех этапах клиентского пути.