
«`html
Применение супермаленьких языковых моделей (STLMs) для устойчивого ИИ трансформирует область NLP
Обработка естественного языка (NLP) имеет множество применений, включая машинный перевод, анализ настроений и разговорные агенты. Возникновение LLMs значительно расширило возможности NLP, сделав эти приложения более точными и эффективными. Однако вычислительные и энергетические требования этих больших моделей вызывают опасения с точки зрения устойчивости и доступности.
Основные вызовы
Основная проблема с текущими большими языковыми моделями заключается в их значительных вычислительных и энергетических требованиях. Эти модели, часто содержащие миллиарды параметров, требуют обширных ресурсов для обучения и развертывания. Этот высокий спрос ограничивает их доступность, что затрудняет использование этих мощных инструментов для многих исследователей и институтов. Необходимы более эффективные модели для достижения высокой производительности без избыточного потребления ресурсов.
Практические решения
Различные методы были разработаны для повышения эффективности языковых моделей. Техники, такие как привязка весов, обрезка, квантизация и дистилляция знаний, были изучены. Привязка весов включает общие веса между различными компонентами модели для уменьшения общего числа параметров. Обрезка удаляет менее значимые веса, создавая более разреженную и эффективную модель. Квантизация уменьшает точность весов и активаций с 32-битных до меньших представлений битов, что уменьшает размер модели и ускоряет обучение и вывод. Дистилляция знаний передает знания от большой «учительской» модели к меньшей «ученической» модели, сохраняя производительность при уменьшении размера.
Исследовательская группа из A*STAR, Национального технологического университета и Университета управления в Сингапуре представила супермаленькие языковые модели (STLMs) для решения неэффективности больших языковых моделей. Эти модели направлены на обеспечение высокой производительности при значительно сокращенном количестве параметров. Команда сосредоточилась на инновационных методах, таких как токенизация на уровне байтов, привязка весов и эффективные стратегии обучения. Их подход направлен на минимизацию количества параметров на 90-95% по сравнению с традиционными моделями, сохраняя при этом конкурентоспособную производительность.
Предложенные STLMs используют несколько передовых техник для достижения своих целей. Токенизация на уровне байтов с механизмом пулинга встраивает каждый символ во входную строку и обрабатывает их через более маленький, более эффективный трансформер. Этот метод значительно уменьшает количество необходимых параметров. Привязка весов общает веса между различными слоями модели, уменьшая количество параметров. Эффективные стратегии обучения гарантируют, что эти модели могут быть эффективно обучены даже на оборудовании для потребителей.
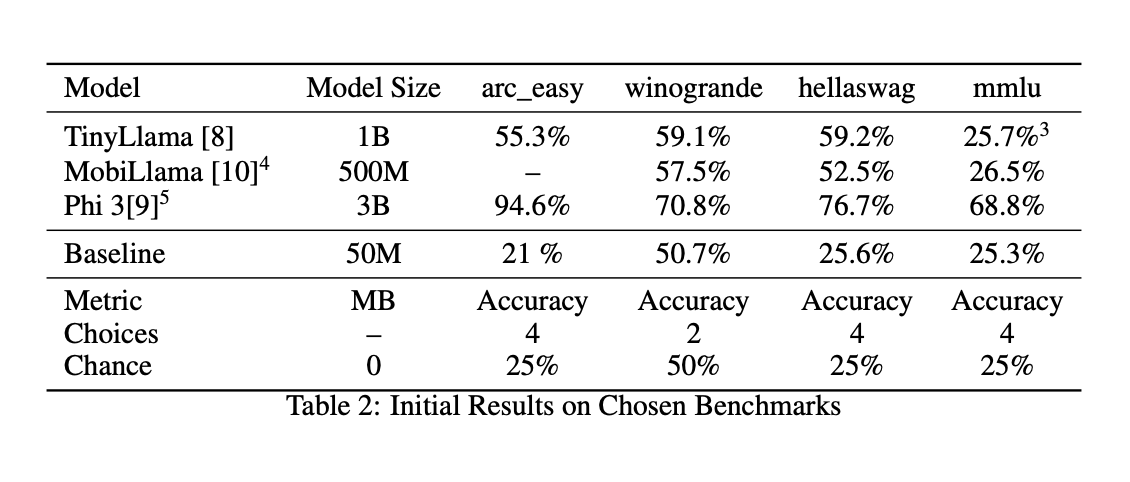
Оценка производительности предложенных STLMs показала многообещающие результаты. Несмотря на их уменьшенный размер, эти модели достигли конкурентных уровней точности на нескольких бенчмарках. Например, модель с 50 миллионами параметров продемонстрировала производительность, сравнимую с гораздо более крупными моделями, такими как TinyLlama (1,1 миллиарда параметров), Phi-3-mini (3,3 миллиарда параметров) и MobiLlama (0,5 миллиарда параметров). В конкретных задачах, таких как ARC (AI2 Reasoning Challenge) и Winogrande, модели показали точность на уровне 21% и 50,7% соответственно. Эти результаты подчеркивают эффективность техник уменьшения параметров и потенциал STLMs обеспечить высокую производительность NLP с более низкими требованиями к ресурсам.
В заключение, исследовательская группа из A*STAR, Национального технологического университета и Университета управления в Сингапуре создала высокопроизводительные и ресурсоэффективные модели, разработав супермаленькие языковые модели (STLMs), сосредоточившись на уменьшении параметров и эффективных методах обучения. Эти STLMs решают критические проблемы вычислительных и энергетических требований, делая передовые технологии NLP более доступными и устойчивыми. Предложенные техники, такие как токенизация на уровне байтов и привязка весов, доказали свою эффективность в поддержании производительности при значительном сокращении количества параметров.
Проверьте статью. Вся заслуга за это исследование принадлежит ученым этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit. Также ознакомьтесь с нашей платформой AI Events здесь.
Статья была опубликована на сайте MarkTechPost.
«`





















