
«`html
Обзор решений в области обработки естественного языка (NLP) в искусственном интеллекте
Значимость NLP в AI
Обработка естественного языка (NLP) в искусственном интеллекте направлена на обучение машин понимать и генерировать человеческий язык. Это включает в себя перевод языка, анализ тональности и суммирование текста. Значительные достижения в этой области привели к разработке больших языковых моделей (LLM), способных обрабатывать огромные объемы текста. Такие возможности открыли пути для выполнения сложных задач, таких как суммирование текстов большого объема и улучшенная генерация информации с использованием поисковых систем (RAG).
Проблемы в оценке производительности LLM
Одной из основных проблем в области NLP является эффективная оценка производительности LLM на задачах, требующих обработки большого объема контента. Традиционные задачи, такие как «Игла в стоге сена», не предоставляют достаточной сложности для выявления возможностей новейших моделей. Оценка качества выходных данных для этих задач затруднена из-за необходимости определения высококачественных референсных суммарирующих текстов и надежных автоматических метрик. Этот недостаток в методах оценки затрудняет точную оценку современных LLM.
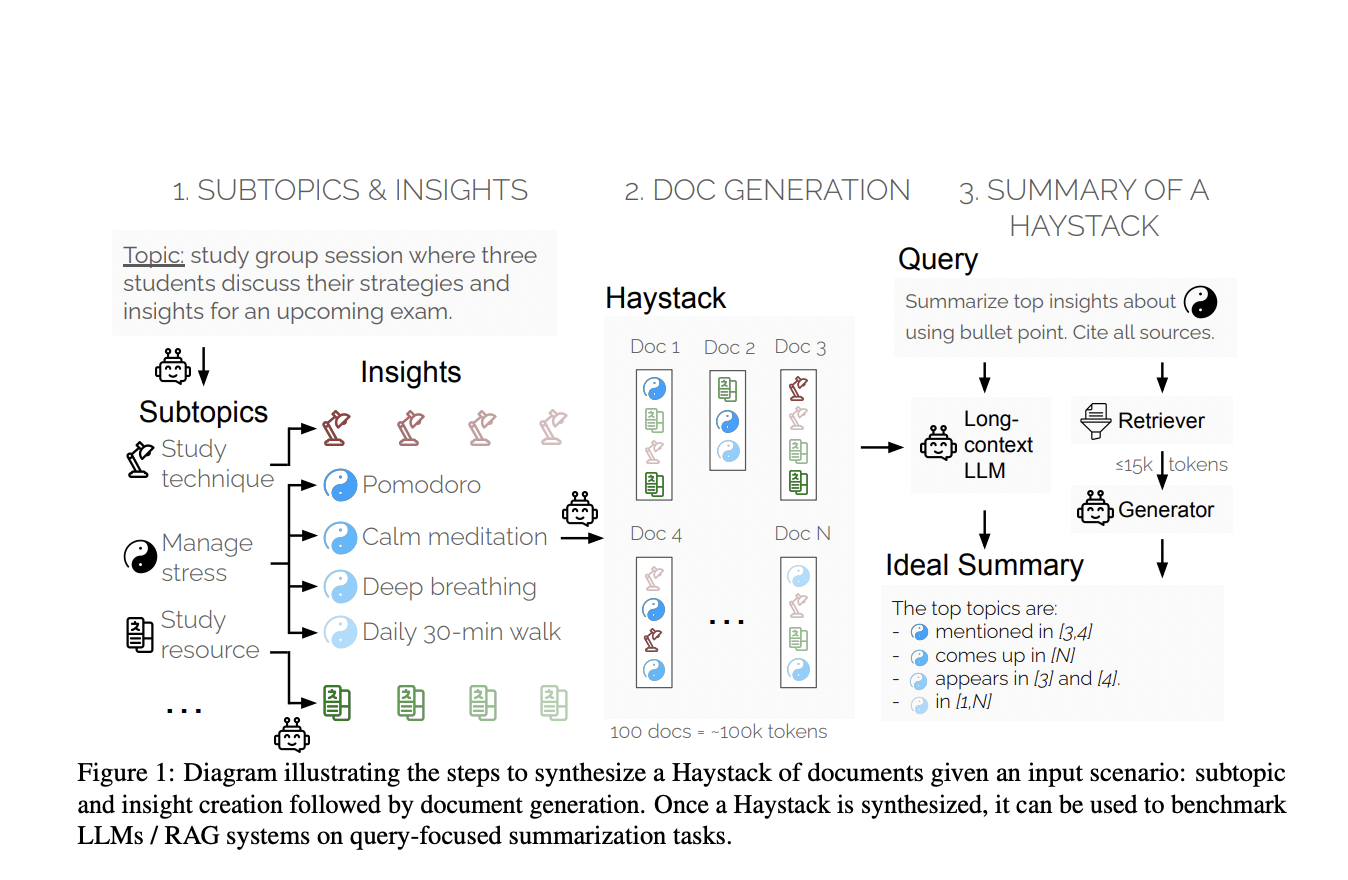
Новый метод оценки SummHay
Исследователи Salesforce AI Research представили новый метод оценки, называемый «Summary of a Haystack» (SummHay) task. Этот метод направлен на более эффективную оценку длинных моделей контекста и систем RAG. Исследователи создали синтетические «стоги сена» документов, чтобы гарантировать повторение определенных идей в этих документах. SummHay требует, чтобы системы обрабатывали эти «стоги», генерировали суммаризированные тексты, точно охватывающие соответствующие идеи, и указывали исходные документы. Такой подход обеспечивает воспроизводимую и комплексную основу для оценки.
Оценка производительности
Крупномасштабная оценка 10 LLM и 50 RAG систем показала, что SummHay task остается значительным вызовом для существующих систем. Например, даже при предоставлении системам оракула о значимости документа, они отстают от человеческой производительности более чем на 10 пунктов по совокупному показателю. Результаты также подчеркнули компромиссы между системами RAG и моделями длинного контекста. RAG системы обычно улучшают качество цитирования за счет охвата идей.
Заключение
Исследование Salesforce AI Research заполняет критический пробел в оценке длинных LLM и систем RAG. SummHay обеспечивает надежную основу для оценки возможностей этих систем, выделяя значительные вызовы и области для улучшения. Несмотря на текущие сложности систем по сравнению с человеческими показателями, это исследование прокладывает путь для будущих разработок, которые в конечном итоге могут превзойти человеческую производительность в суммировании длинных текстов.
Источник: MarkTechPost
Ссылка на исследование: GitHub
Подпишитесь на наш Telegram-канал и нашу страницу в Twitter для получения новостей о развитии ИИ.
«`



















