
«`html
Введение в мультимодальные встраивания: новая концепция в области искусственного интеллекта
Одним из важных достижений в области искусственного интеллекта являются мультимодальные модели с большой емкостью по языку (MLLMs), которые объединяют вербальное и визуальное понимание для создания более точных представлений мультимодальных входных данных. Через интеграцию данных из различных источников, включая текст и изображения, эти модели улучшают понимание сложных взаимосвязей между различными видами модалей. Благодаря этой интеграции стали возможны сложные задачи, требующие тщательного понимания множества данных. В результате MLLMs являются важной областью интереса для современных исследований в области искусственного интеллекта.
Основные вызовы и пути решения в мультимодальном обучении
Основным вызовом в мультимодальном обучении является достижение эффективного представления мультимодальной информации. Текущие исследования включают в себя такие структуры, как CLIP, который выравнивает визуальные и языковые представления с использованием контрастного обучения на парах изображений и текста. Модели, такие как BLIP, KOSMOS, LLaMA-Adapter и LLaVA, расширяют LLMs для работы с мультимодальной информацией. Эти методы часто используют отдельные кодировщики для текста и изображений, что приводит к плохой интеграции входных данных. Более того, они требуют обширных и дорогостоящих данных для мультимодального обучения и нуждаются в помощи в обширном языковом понимании и выполнении сложных визуально-языковых задач, не достигая универсальных, эффективных мультимодальных вставок.
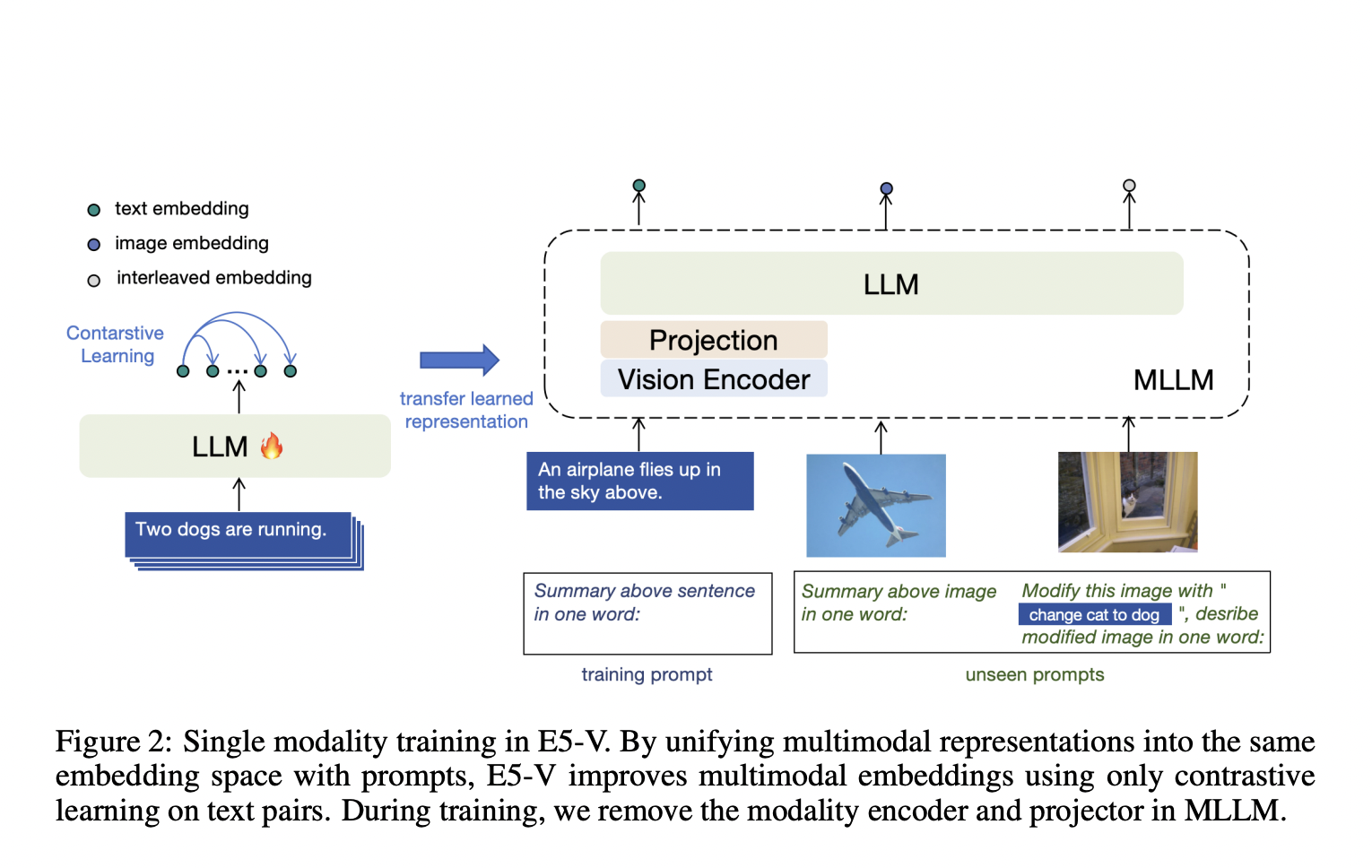
Новый подход к мультимодальным встраиваниям: E5-V framework
Для преодоления этих ограничений исследователи из Университета Бейхан и корпорации Microsoft представили E5-V framework, разработанный для адаптации MLLMs для универсальных мультимодальных встраиваний. Этот инновационный подход использует обучение с использованием одномодальности на парах текста, существенно снижая затраты на обучение и устраняя необходимость в сборе мультимодальных данных. Сосредоточившись на парах текста, E5-V framework демонстрирует существенные улучшения в представлении мультимодальных входных данных по сравнению с традиционными методами, предлагая многообещающий вариант для будущих разработок в этой области.
Преимущества E5-V framework и его практическое применение
E5-V framework использует новый метод представления на основе подсказок для объединения мультимодальных встраиваний в единое пространство. В процессе обучения модель использует исключительно пары текста, упрощая процесс и сокращая затраты, связанные с сбором мультимодальных данных. Главное новшество заключается в инструкции MLLMs представлять мультимодальные входы как слова, что позволяет модели выполнять высокоточные задачи, такие как поиск объединенных изображений. Путем объединения различных встраиваний в одно пространство на основе их значений E5-V framework повышает надежность и универсальность мультимодальных представлений.
Демонстрация выдающейся производительности E5-V framework
E5-V продемонстрировал впечатляющие результаты в различных задачах, включая поиск текста-изображения, поиск объединенных изображений, встраивание предложений и поиск изображений. Фреймворк превосходит современные модели в нескольких бенчмарках. Например, в задачах нулевого поиска изображений E5-V превосходит CLIP ViT-L на 12.2% на Flickr30K и на 15.0% на COCO с Recall@1, демонстрируя свою высокую способность интегрировать визуальную и языковую информацию. Кроме того, E5-V значительно улучшает задачи поиска объединенных изображений, превосходя текущий современный метод iSEARLE-XL на 8.50% на Recall@1 и на 10.07% на Recall@5 на наборе данных CIRR. Эти результаты подчеркивают эффективность фреймворка в точном представлении взаимозависимых входных данных и сложных взаимодействий.
Заключение: новый этап в развитии мультимодального обучения
Фреймворк E5-V представляет собой значительное достижение в области мультимодального обучения. За счет использования одномодального обучения и метода представления на основе подсказок E5-V решает ограничения традиционных подходов, предоставляя более эффективное и эффективное решение для мультимодальных встраиваний. Эти исследования демонстрируют потенциал MLLMs для революционизации задач, требующих интегрированного визуального и языкового понимания, проложив путь для будущих инноваций в области искусственного интеллекта. Работа исследовательских групп из Университета Бейхан и корпорации Microsoft подчеркивает трансформационный потенциал их подхода, устанавливая новый стандарт для мультимодальных моделей.
Проверьте статью, Карточку модели и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Кроме того, не забудьте подписаться на нас в Twitter и присоединиться к нашим каналам в Telegram и LinkedIn. Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit
Найдите предстоящие вебинары по искусственному интеллекту здесь.
Опубликовано на MarkTechPost.
«`




















