
«`html
Исследование Microsoft: MedFuzz — новый метод оценки надежности ML в медицинском вопросно-ответном приложении
Системы вопросно-ответной медицинской тематики стали предметом исследований в связи с их потенциалом помощи врачам в точных диагнозах и выборе лечения. Эти системы используют большие языковые модели (LLM) для обработки огромного объема медицинской литературы, позволяя им отвечать на клинические вопросы на основе существующих знаний. Данная область исследований обещает улучшить предоставление медицинской помощи, предоставляя врачам быструю и надежную информацию из обширных медицинских баз данных, в конечном итоге улучшая процессы принятия решений.
Вызовы в оценке работы LLM в медицинских системах вопросно-ответной тематики
Один из ключевых вызовов в разработке систем вопросно-ответной медицинской тематики заключается в обеспечении того, что производительность LLM в контролируемых тестах преобразуется в надежные результаты в реальных клинических настройках. Нынешние тесты, такие как MedQA, часто основаны на упрощенных представлениях клинических случаев, таких как множественный выбор вопросов, происходящих от экзаменов, например, USMLE. Хотя эти тесты показали, что LLM может достичь высокой точности, существует опасение, что эти модели могут необходимо обобщить для сложных реальных клинических сценариев, где разнообразие пациентов и сложность ситуаций могут привести к неожиданным результатам.
Оценка производительности LLM в медицине
Для оценки производительности LLM в медицине используются несколько методов. Один из наиболее широко используемых инструментов — это бенчмарк MedQA-USMLE для тестирования точности моделей в вопросно-ответной медицинской тематике. Однако тесты, подобные MedQA, ограничены своей неспособностью полностью реплицировать сложности реальных клинических сред. Эти тесты упрощают случаи пациентов в форматы множественного выбора, сжимая тонкости фактических медицинских ситуаций, что приводит к разрыву между производительностью бенчмарка и его применимостью в реальном мире.
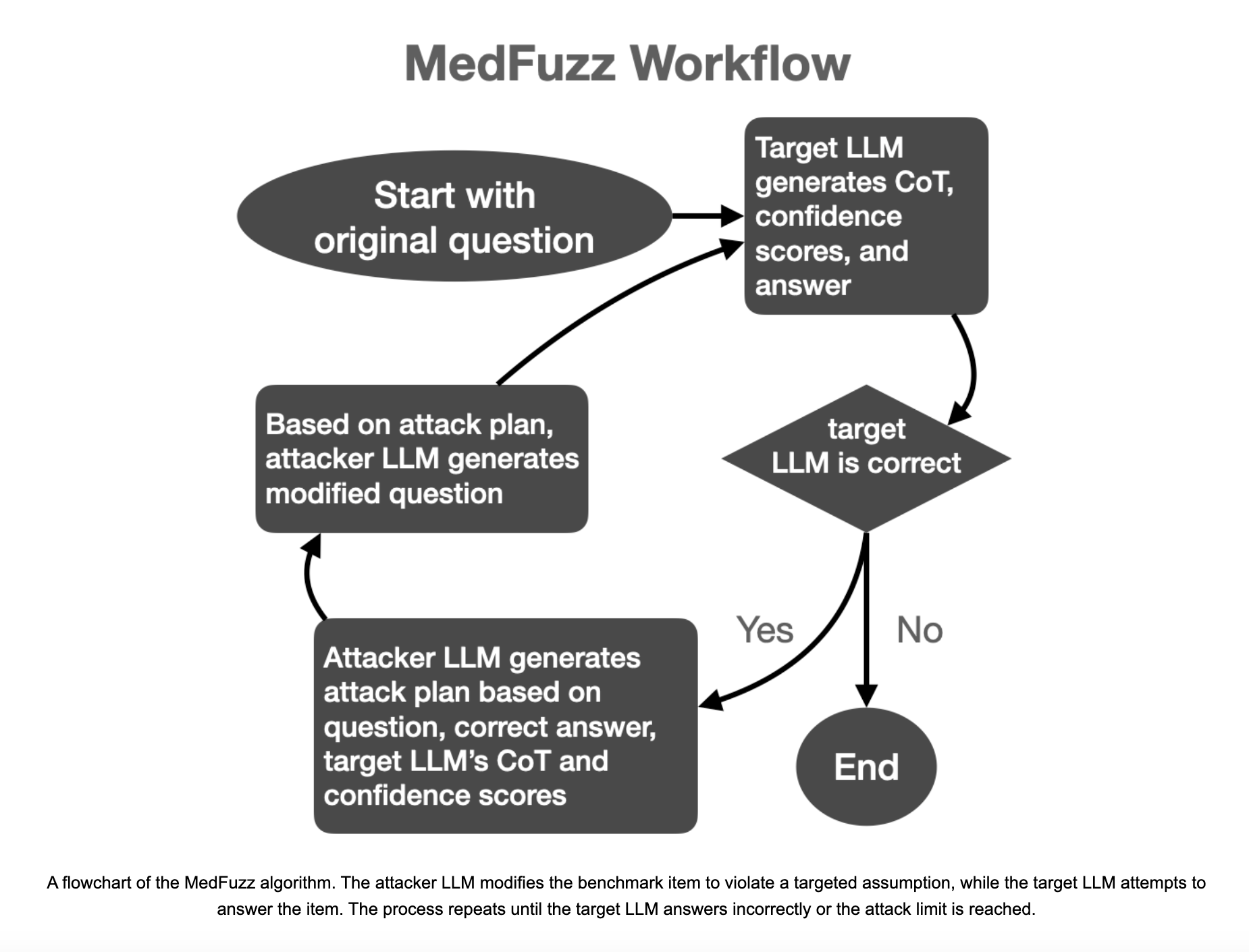
MedFuzz: новый метод оценки надежности LLM
Исследователи из Microsoft Research, Massachusetts Institute of Technology, Johns Hopkins University и Helivan Research представили инновационный метод MedFuzz для проверки надежности LLM путем изменения вопросов из медицинских бенчмарков таким образом, чтобы нарушать предположения, лежащие в их основе. Метод занимается определением уязвимостей путем внесения характеристик пациента или других клинических деталей, которые могут не соответствовать упрощенным предположениям бенчмарков, для оценки того, смогут ли LLM все еще точно работать в более сложных и реалистичных клинических ситуациях.
Заключение
Метод MedFuzz проливает свет на ограничения текущих оценок LLM в медицинской вопросно-ответной тематике. В то время как бенчмарки, такие как MedQA, помогли разработке высокопроизводительных моделей, они не улавливают тонкостей реальной медицины. MedFuzz сокращает этот разрыв, предлагая способ тестировать модели против более сложных сценариев. Это исследование подчеркивает необходимость непрерывного совершенствования методов оценки LLM для обеспечения их безопасного и эффективного использования в здравоохранении.
Ознакомьтесь с Paper and Details. Вся заслуга за это исследование принадлежит его ученым. Также не забудьте следить за нами в Twitter и присоединиться к нашему каналу в Telegram и LinkedIn.
Не забудьте присоединиться к нашему сообществу в Reddit: 50k+ ML SubReddit
Бесплатный вебинар по ИИ: «SAM 2 for Video: How to Fine-tune On Your Data» (Ср, 25 сентября, 4:00 — 4:45 EST)
Источник: MarkTechPost