
Развитие ИИ в сфере крупных языковых моделей
Проблема:
Большие языковые модели (LLM) используются в областях, требующих сложного мышления, таких как математическое решение проблем и программирование. Однако их способность к самокоррекции является ключевым аспектом развития. Многие LLM, несмотря на знание необходимого для решения сложных задач, часто ошибаются при попытке его применения, что приводит к неполным или некорректным ответам.
Решение:
Google DeepMind представил новый подход под названием Self-Correction via Reinforcement Learning (SCoRe), который обучает LLM улучшать свои ответы, используя собственные данные без необходимости внешнего наблюдения или моделей-подтверждений. Этот метод позволяет модели самостоятельно обнаруживать и исправлять ошибки, значительно улучшая ее способность к самокоррекции.
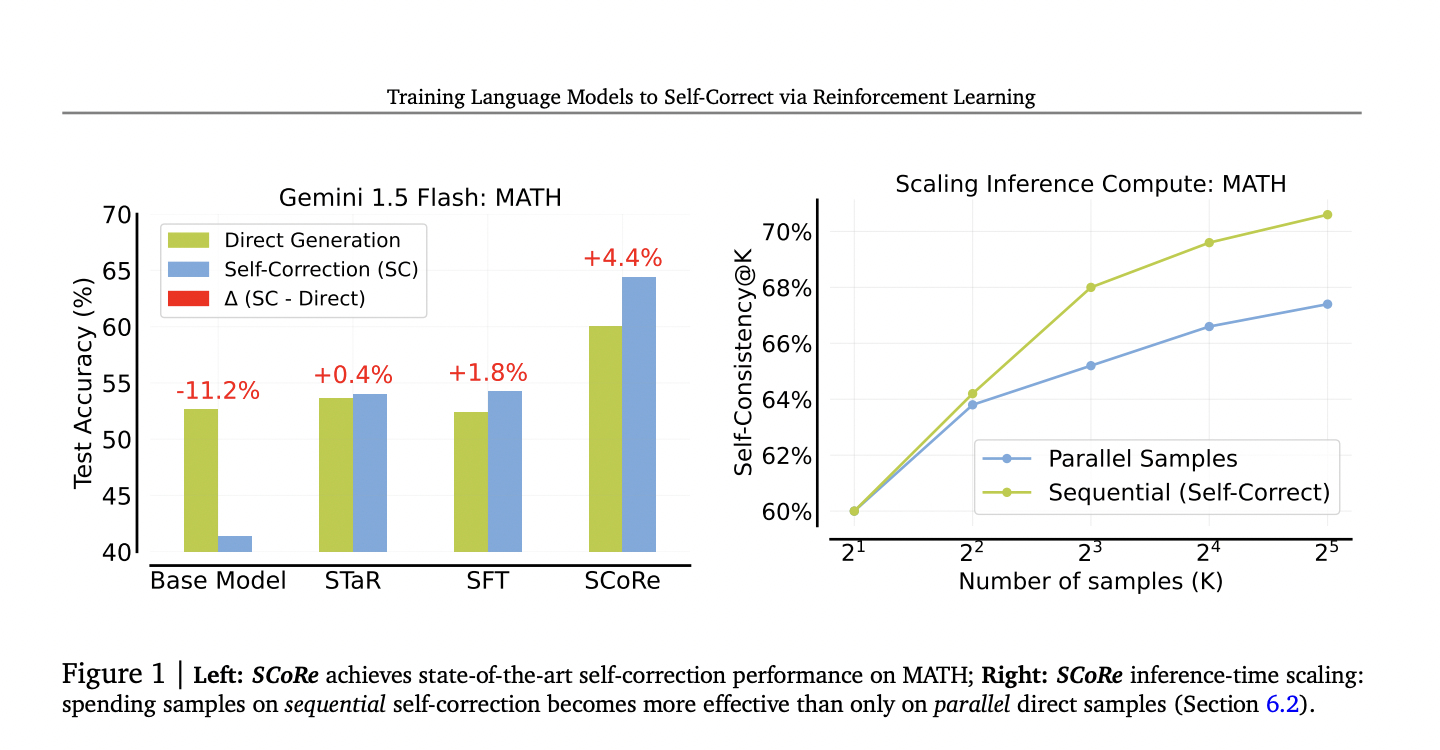
Результаты:
Применение метода SCoRe показало значительное улучшение производительности LLM в самокоррекции. Модели Gemini 1.0 Pro и 1.5 Flash смогли добиться улучшения точности самокоррекции на 15,6% для задач математического рассуждения и на 9,1% для задач программирования. Эти результаты подчеркивают эффективность метода по сравнению с традиционными методами обучения под контролем.
Заключение:
Методика SCoRe открывает новые возможности для улучшения способности к самокоррекции LLM. Этот подход помогает увеличить точность и эффективность модели в решении сложных задач, делая ее более надежной для практического применения.



















