
«`html
Продвижения в области NLP привели к разработке больших языковых моделей (LLM), способных выполнять сложные задачи, связанные с языком, с высокой точностью.
Эти продвижения открыли новые возможности в технологиях и коммуникациях, позволяя более естественное и эффективное взаимодействие человека с компьютером.
Проблема в NLP
Существенной проблемой в NLP является зависимость от человеческих аннотаций для оценки моделей. Сбор этих данных дорогостоящ и затратен по времени. Как модели улучшаются, ранее собранные аннотации могут потребовать обновления, уменьшая их полезность для оценки новых моделей. Это создает постоянную потребность в свежих данных, что представляет вызовы для масштабирования и поддержания эффективной оценки моделей. Решение этой проблемы критично для продвижения технологий NLP и их применений.
Текущие методы оценки моделей
Типичные методы оценки моделей включают сбор большого количества человеческих предпочтений по ответам моделей и использование автоматических метрик для задач с эталонными ответами. Однако эти методы имеют ограничения, особенно для сложных задач, где возможны несколько верных ответов. Высокая вариация в человеческих оценках и связанные с ними затраты подчеркивают необходимость более эффективных и масштабируемых техник оценки.
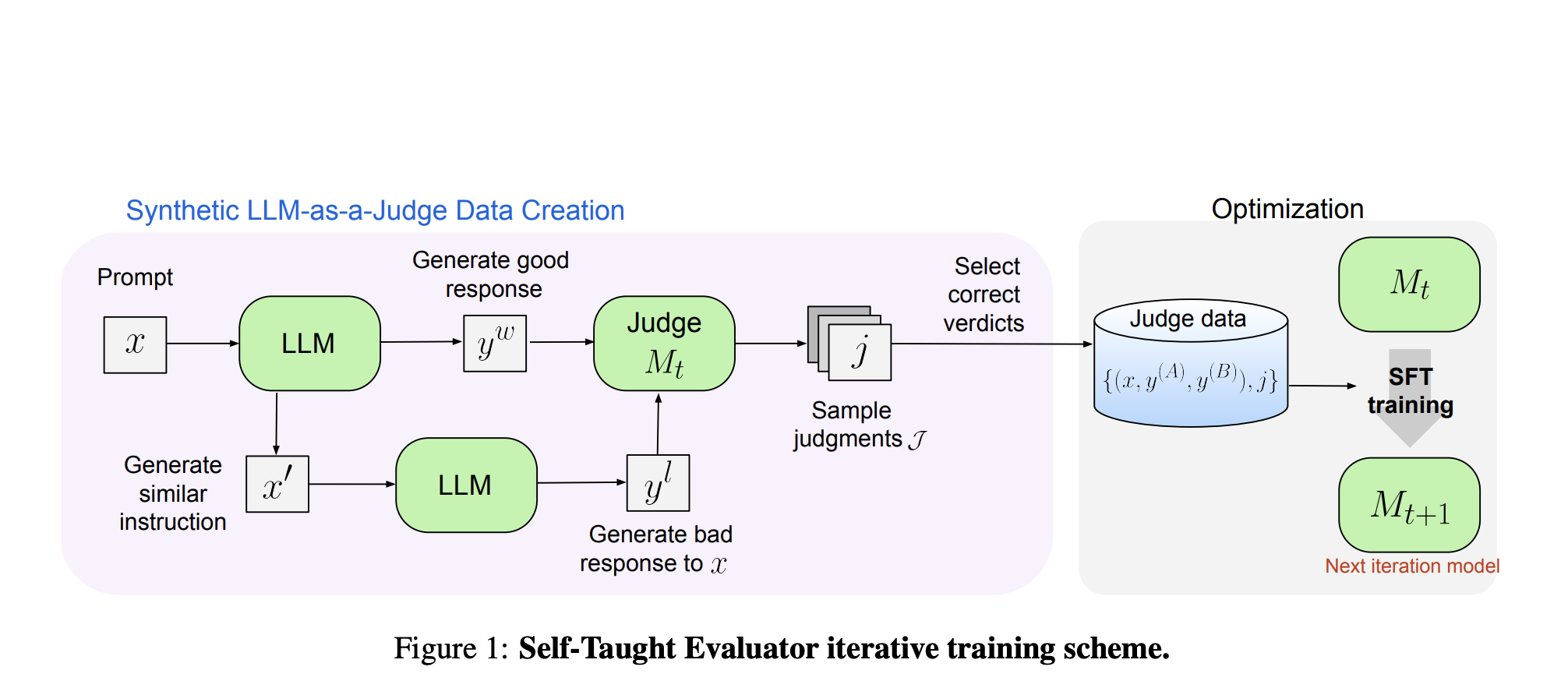
Новый подход: «Самообучающийся оценщик»
Исследователи из Meta FAIR предложили новый подход, который устраняет необходимость в человеческих аннотациях, используя синтетически сгенерированные данные для обучения. Этот метод начинается с базовой модели, которая генерирует контрастные синтетические пары предпочтений. Модель затем оценивает эти пары и итеративно улучшается, используя свои оценки для улучшения своей производительности в последующих итерациях. Этот подход снижает зависимость от человеческих аннотаций, используя способность модели генерировать и оценивать данные.
Результаты и перспективы
Производительность «Самообучающегося оценщика» была протестирована с использованием модели Llama-3-70B-Instruct. Метод улучшил точность модели на бенчмарке RewardBench с 75.4 до 88.7, превзойдя производительность моделей, обученных с использованием человеческих аннотаций. Данный значительный прогресс демонстрирует эффективность синтетических данных в улучшении оценки модели. Исследователи также провели несколько итераций, дополнительно улучшая возможности модели. Итоговая модель достигла точности 88.3 при одном выводе и 88.7 при голосовании большинства, показывая ее надежность и устойчивость.
Заключение
Самообучающийся оценщик предлагает масштабируемое и эффективное решение для оценки моделей NLP. Путем использования синтетических данных и итеративного самоулучшения он решает вызовы, связанные с зависимостью от человеческих аннотаций, и идет в ногу с быстрыми продвижениями в разработке языковых моделей. Этот подход улучшает производительность модели и уменьшает зависимость от человеческих данных, открывая путь к более автономным и эффективным системам NLP. Работа исследовательской команды Meta FAIR является значительным шагом вперед в стремлении к более продвинутым и автономным методам оценки в области NLP.
Проверьте статью. Вся заслуга за это исследование принадлежит его авторам. Также, не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подпреддиту по машинному обучению.
Находите предстоящие вебинары по ИИ здесь.
Arcee AI выпустил DistillKit: Open Source инструмент, упрощающий дистилляцию моделей для создания эффективных малых языковых моделей.
Статья Meta представляет Самообучающихся Оценщиков: Новый подход в области ИИ, направленный на улучшение оценки без человеческих аннотаций и превосходящий обычно используемых судей LLM, таких как GPT-4.
Это был перевод статьи с сайта MarkTechPost.