
«`html
Преобразования при помощи МЕЛЛЕ в области синтеза речи
В области больших языковых моделей (LLM) произошли значительные изменения в генерации текста, что побудило исследователей исследовать их потенциал в области синтеза звука. Вызов заключается в адаптации этих моделей для выполнения задачи текст в речь (TTS), сохраняя при этом высококачественный результат. Текущие методологии, такие как языковые модели нейронных кодеков, например, VALL-E, сталкиваются с несколькими ограничениями. К ним относятся низкая верность по сравнению с мел-спектрограммами, проблемы устойчивости, обусловленные случайными стратегиями выборки, и необходимость сложных процессов двухпроходного декодирования. Эти вызовы препятствуют эффективности и качеству синтеза аудио, особенно в нулевых TTS-задачах, которые требуют мультиязычных, мультиговорящих и мультидоменных возможностей.
Решения для синтеза текста в речь (TTS)
Исследователи пытались решить вызовы в синтезе текста в речь (TTS). Традиционные методы включают конкатенативные системы, которые собирают аудиофрагменты, и параметрические системы, которые используют акустические параметры для синтеза речи. Системы конечно-конечного нейронного TTS, такие как Tacotron, TransformerTTS и FastSpeech, упростили процесс, генерируя мел-спектрограммы напрямую из текста.
Недавние достижения сосредоточены на возможностях нулевого TTS. Модели, такие как VALL-E, рассматривают TTS как условную языковую задачу, используя нейронные кодековые коды в качестве промежуточных представлений. VALL-E X расширила этот подход на мультиязычные сценарии. Mega-TTS предложила разделение речевых атрибутов для более эффективного моделирования. Другие модели, такие как ELLA-V, RALL-E и VALL-E R, стремились улучшить устойчивость и стабильность.
Некоторые исследователи исследовали неавторегрессивные подходы для более быстрого вывода, такие как параллельная схема декодирования SoundStorm и модель диффузии StyleTTS 2. Однако эти методы часто испытывают трудности с сохранением качества аудио или эффективной обработкой многоговорящих, мультиязычных сценариев.
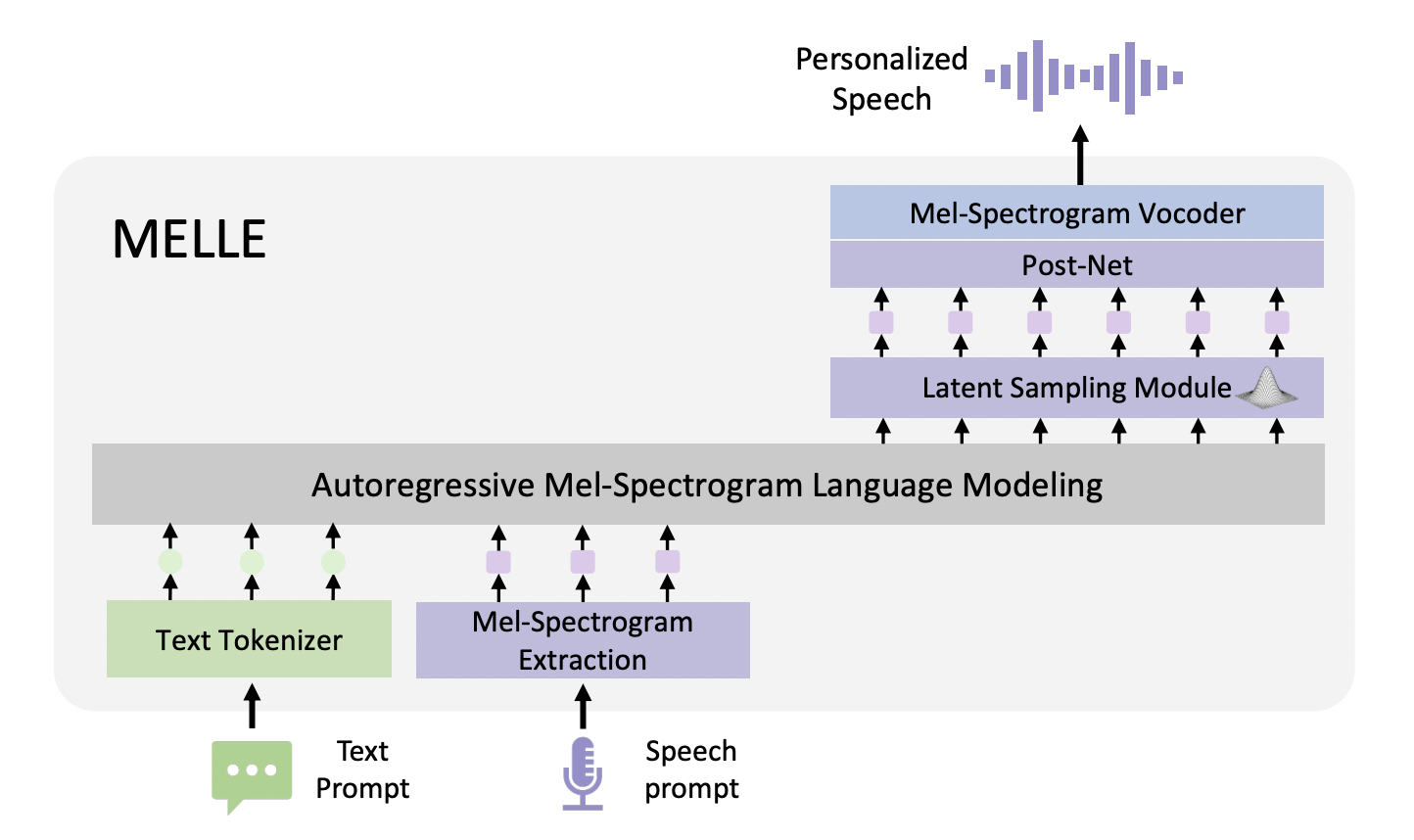
Исследователи из Китайского университета Гонконга и корпорации Microsoft представляют MELLE, уникальный подход к синтезу текста в речь, использующий непрерывные токены на основе мел-спектрограмм. Этот метод направлен на преодоление ограничений дискретных кодековых кодов путем непосредственного генерирования непрерывных кадров мел-спектрограмм из входного текста. Подход решает две ключевые проблемы: установление соответствующей цели обучения для непрерывных представлений и обеспечение механизмов выборки в непрерывном пространстве.
Для решения этих вызовов MELLE использует функцию потерь регрессии с функцией потерь потока спектрограммы вместо потерь перекрестной энтропии. Эта новая функция потерь помогает более эффективно моделировать вероятностное распределение непрерывных токенов. Кроме того, MELLE включает вариационный вывод для облегчения механизмов выборки, улучшая разнообразие вывода и устойчивость модели.
Модель работает как однопроходная система нулевого TTS, авторегрессивно предсказывая кадры мел-спектрограммы на основе предыдущих мел-спектрограмм и текстовых токенов. Этот подход направлен на устранение проблем устойчивости, связанных с выборкой дискретных кодековых кодов, потенциально предлагая повышенную верность и эффективность в синтезе речи.
Архитектура MELLE интегрирует несколько инновационных компонентов для эффективного синтеза текста в речь. Она использует слой встраивания, авторегрессивный декодер трансформера и уникальный модуль выборки латентов, улучшающий разнообразие вывода. Модель включает слой прогнозирования остановки и сверточную пост-сеть для улучшения спектрограммы. В отличие от языковых моделей нейронных кодеков, MELLE не требует отдельной неавторегрессивной модели, что улучшает эффективность. Она может генерировать несколько кадров мел-спектрограммы за шаг, дополнительно улучшая производительность. Архитектура завершается вокодером, который преобразует мел-спектрограмму в волну, предлагая упрощенный однопроходный подход, который потенциально превосходит предыдущие методы как по качеству, так и по эффективности.
Преимущества MELLE
MELLE демонстрирует превосходную производительность в нулевых задачах синтеза речи по сравнению с VALL-E и его вариантами. Она значительно превосходит обычный VALL-E в устойчивости и схожести говорящего, достигая 47,9% относительного снижения WER-H на задаче продолжения и 64,4% снижения на задаче между предложениями. В то время как VALL-E 2 показывает сравнимые результаты, MELLE проявляет лучшую устойчивость и схожесть говорящего в задаче продолжения, подчеркивая ее превосходные возможности обучения в контексте.
Производительность MELLE остается постоянно высокой даже с увеличенными факторами снижения, что позволяет более быстрое обучение и вывод. Модель превосходит большинство последних работ как в устойчивости, так и в схожести говорящего, даже с более крупными факторами снижения. MELLE-limited, обученная на более малом корпусе, все равно превосходит VALL-E и его варианты, за исключением VALL-E 2. Использование нескольких выборок с более крупным фактором снижения может улучшить производительность и сократить время вывода, как показывают результаты пятикратной выборки, которые демонстрируют стабильную высокую устойчивость при различных настройках фактора снижения.
Заключение
Данное исследование представляет MELLE, представляющее собой значительный прогресс в нулевом синтезе текста в речь, представляя подход основанный на непрерывном акустическом представлении. Путем прямого предсказания мел-спектрограмм из содержания текста и речевых подсказок он устраняет необходимость дискретной векторной квантовизации и двухпроходных процедур, характерных для языковых моделей нейронных кодеков, таких как VALL-E. Включение латентной выборки и функции потерь потока спектрограммы позволяет MELLE производить более разнообразные и устойчивые предсказания. Эффективность модели может быть дополнительно улучшена путем настройки фактора снижения для более быстрого декодирования. Следует отметить, что MELLE достигает результатов, сравнимых с человеческой производительностью в субъективных оценках, что является значительным шагом вперед в области синтеза речи.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему подразделу ML на Reddit.
Использование ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте MELLE: A Novel Continuous-Valued Tokens-based Language Modeling Approach for Text-to-Speech Synthesis (TTS).
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`

















