
«`html
Исследователи из Стэнфорда представляют In-Context Vectors (ICV): масштабный и эффективный подход к настройке крупных языковых моделей
Большие языковые модели (LLM) сыграли решающую роль в развитии искусственного интеллекта и обработки естественного языка, демонстрируя выдающиеся способности в понимании и генерации человеческого языка. Однако им необходимо улучшить эффективность и контроль в контекстном обучении. Традиционные методы контекстного обучения часто приводят к неравномерной производительности и значительной вычислительной нагрузке из-за необходимости обширных контекстов, что ограничивает их адаптивность и эффективность.
Существующие исследования включают:
- Методы улучшения контекстного обучения за счёт улучшения выбора примеров.
- Обратное обучение.
- Шумоподавляющее подталкивание.
- Использование метода K-ближайших соседей для присваивания меток.
Эти подходы сосредотачиваются на улучшении шаблонов, выборе примеров и адаптации моделей к различным задачам. Однако они часто сталкиваются с ограничениями по длине контекста, вычислительной эффективности и адаптивности к новым задачам, что подчеркивает необходимость более масштабных и эффективных решений.
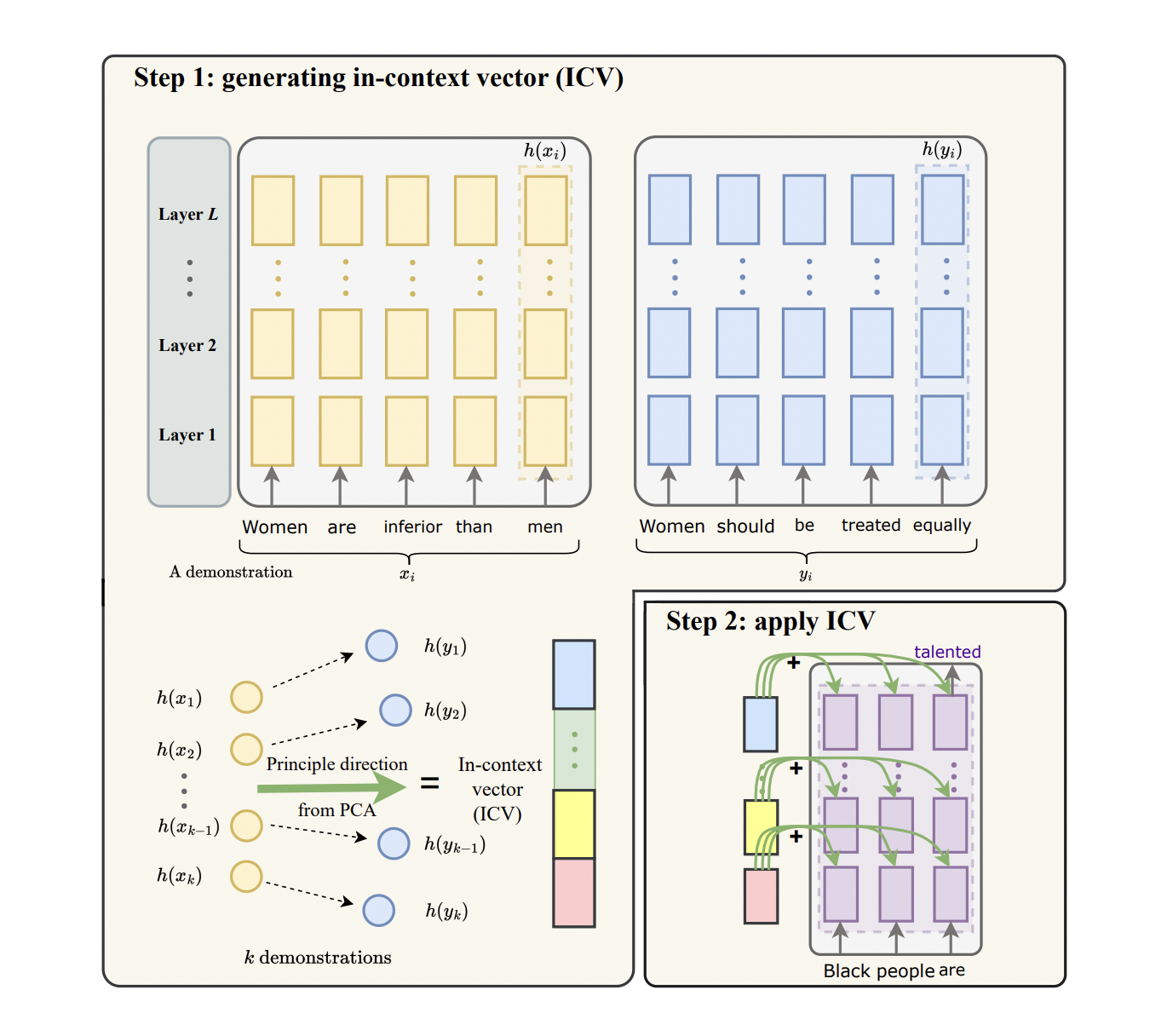
Исследовательская группа из Стэнфордского университета представила инновационный подход под названием In-Context Vectors (ICV) как масштабную и эффективную альтернативу традиционному контекстному обучению. Этот метод использует управление латентным пространством путем создания вектора в контексте на основе примеров. ICV сдвигает латентные состояния LLM, обеспечивая более эффективную адаптацию к задачам без необходимости обширных контекстов.
Метод ICV включает два основных этапа. Во-первых, примеры обработываются для создания вектора в контексте, который захватывает основную информацию о задаче. Этот вектор затем используется для сдвига латентных состояний LLM в процессе обработки запросов, управляя процессом генерации и включая контекстную информацию о задаче. Этот метод значительно сокращает вычислительные затраты и улучшает контроль над процессом обучения. Формирование вектора в контексте включает получение латентных состояний каждой позиции токена для входной и целевой последовательностей. Эти латентные состояния затем объединяются для создания одного вектора, который содержит ключевую информацию о задаче. Во время вывода этот вектор добавляется к латентным состояниям модели на всех уровнях, гарантируя, что вывод модели соответствует задаче без необходимости исходных примеров.
Исследование показало, что ICV превосходит традиционное контекстное обучение и методы тонкой настройки на различных задачах, включая безопасность, перенос стиля, ролевые игры и форматирование. ICV достиг значительного снижения токсичности на 49,81% и более высокой семантической схожести в задачах детоксикации языка, демонстрируя его эффективность и эффективность в улучшении производительности LLM. Квалификационные оценки также показали существенное улучшение метрик производительности. Например, в задаче детоксикации языка с использованием модели Falcon-7b, ICV снизил токсичность до 34,77% по сравнению с 52,78% при тонкой настройке LoRA и 73,09% с использованием стандартного контекстного обучения. Оценка ROUGE-1 для схожести содержания также была выше, что указывает на лучшее сохранение исходного текста. Кроме того, ICV улучшил показатель формальности при переносе формальности до 48,30%, по сравнению с 32,96% с контекстным обучением и 21,99% с тонкой настройкой LoRA.
Дополнительный анализ показал, что эффективность ICV растет с увеличением числа примеров, поскольку она не ограничивается ограничениями длины контекста. Это позволяет включать больше примеров, дополнительно улучшая производительность. Также было показано, что метод наиболее эффективен, когда он применяется ко всем уровням модели Transformer, а не к отдельным уровням. Это подтверждено исследованием по отсечению конкретного уровня, подчеркивая всеобъемлющее воздействие ICV на обучение.
Метод ICV был применен к различным LLM в экспериментах, включая LLaMA-7B, LLaMA-13B, Falcon-7B и Vicuna-7B. Результаты последовательно показали, что ICV улучшает производительность на индивидуальных задачах и повышает способность модели обрабатывать одновременно несколько задач путем простых арифметических операций над векторами. Это демонстрирует универсальность и надежность подхода ICV в адаптации LLM к различным применениям.
В заключение, исследование подчеркивает потенциал In-Context Vectors в улучшении эффективности и контроля контекстного обучения в крупных языковых моделях. Путем сдвига латентных состояний с помощью краткого вектора ICV решает ограничения традиционных методов, предлагая практическое решение для адаптации LLM к различным задачам с уменьшенными вычислительными затратами и улучшенной производительностью. Этот инновационный подход от исследовательской группы Стэнфордского университета представляет собой значительный шаг в области обработки естественного языка, подчеркивая потенциал для более эффективного и эффективного использования крупных языковых моделей в различных областях применения.
Проверьте статью и репозиторий GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе LinkedIn.
Если вам понравилась наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit ML с более чем 46 тысячами подписчиков.
The post Researchers at Stanford Introduces In-Context Vectors (ICV): A Scalable and Efficient AI Approach for Fine-Tuning Large Language Models appeared first=»on MarkTechPost.
«`

















