
«`html
FlashAttention-3: новейшее решение для устранения узких мест в слое внимания в архитектуре Transformer
FlashAttention-3, последний релиз в серии FlashAttention, разработан для устранения узких мест в слое внимания в архитектуре Transformer. Эти узкие места критически влияют на производительность больших языковых моделей (LLM) и приложений, требующих обработки длинного контекста.
Основные техники улучшения скорости внимания на GPU Hopper включают:
- Эксплуатацию асинхронности Tensor Cores и TMA для перекрытия вычислений и перемещения данных
- Перемежение блочного умножения матриц и операций softmax
- Использование несогласованной обработки для поддержки аппаратного обеспечения для вычислений низкой точности FP8
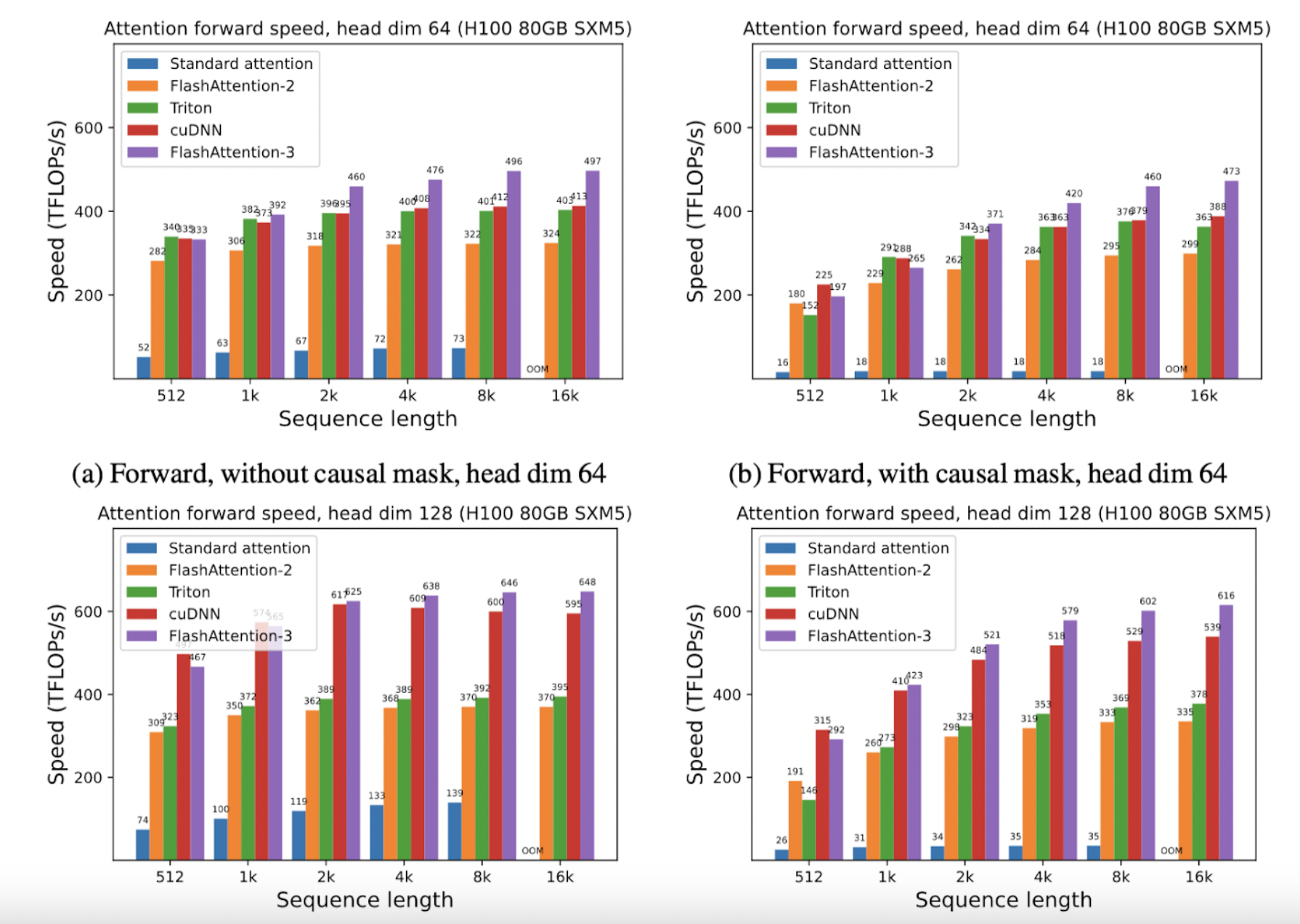
FlashAttention-3 значительно использует вычисления низкой точности FP8, что удваивает пропускную способность Tensor Core по сравнению с FP16. Это увеличивает скорость вычислений и точность за счет уменьшения ошибки квантования через несогласованную обработку.
FlashAttention-3 в 1,5-2 раза быстрее, чем FlashAttention-2 с FP16, достигая до 740 TFLOPS, что составляет 75% от теоретического максимума FLOPs на GPU H100. С FP8 FlashAttention-3 достигает близких к 1,2 PFLOPS, значительного скачка производительности с ошибкой в 2,6 раза меньше по сравнению с базовым вниманием FP8.
Эти усовершенствования основаны на использовании библиотеки CUTLASS от NVIDIA, которая предоставляет мощные абстракции, позволяющие FlashAttention-3 использовать возможности GPU Hopper. Переписав FlashAttention, чтобы включить эти новые функции, AI Lab разблокировал значительные приросты эффективности, позволяя новые возможности моделей, такие как расширенная длина контекста и улучшенная скорость вывода.
Выводы
Релиз FlashAttention-3 представляет собой перелом в проектировании и реализации механизмов внимания в больших языковых моделях. AI Lab продемонстрировало, как целенаправленные оптимизации могут привести к значительному улучшению производительности, тесно сочетая алгоритмические инновации с аппаратными достижениями.
Подробнее о проекте можно узнать на нашем блоге, в статье и на GitHub.
«`

















