
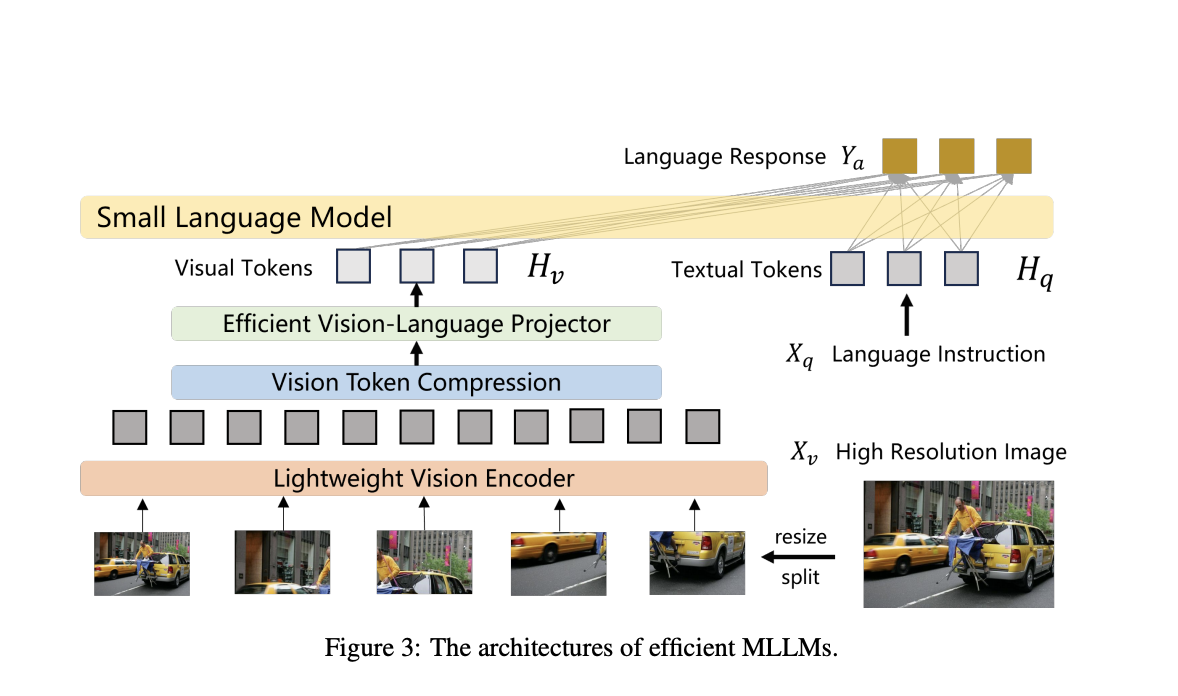
«`html
Мультимодальные крупные языковые модели (MLLMs)
Мультимодальные крупные языковые модели (MLLMs) – передовые инновации в области искусственного интеллекта, которые объединяют возможности языковых и визуальных моделей для решения сложных задач, таких как визуальный ответ на вопросы и описание изображений.
Проблема
Главная проблема MLLMs – это значительные требования к ресурсам, что существенно затрудняет их широкое применение.
Решения
Для решения этих проблем сосредотачиваются на оптимизации эффективности MLLMs, включая уменьшение размера моделей и оптимизацию вычислительных стратегий.
Категоризация прогресса
Исследование категоризирует прогресс в области архитектуры, обработки изображений, эффективности языковых моделей, методов обучения, использования данных и практических применений.
Сжатие визуальных токенов
Техники, такие как сжатие визуальных токенов, существенно снижают вычислительную нагрузку путем сжатия высокоразрешенных изображений в управляемые патч-функции.
Обучение и производительность
Эффективные MLLMs могут быть обучены в академических условиях, с некоторыми моделями, обученными всего за 23 часа с использованием 8 A100 GPU.
Улучшение производительности
Модели, такие как LLaVA-UHD, поддерживают обработку изображений с разрешением до шести раз большим, используя только 94% вычислений по сравнению с предыдущими моделями, что демонстрирует значительное улучшение эффективности.
Эффективные архитектуры
MLLMs используют более легкие архитектуры, специализированные компоненты для повышения эффективности и новые методы обучения для достижения заметного улучшения производительности.
Уменьшение информации о признаках
Техники, такие как funnel transformer и Set Transformer, уменьшают размерность входных признаков, сохраняя при этом важную информацию, улучшая вычислительную эффективность.
Понижение внимания
Кернелизация и методы с низким рангом преобразуют и разложат высокоразмерные матрицы, делая механизм внимания более эффективным.
Понимание документов и видео
Эффективные MLLMs применяются в понимании документов и видео, решая задачи обработки изображений и видео высокого разрешения.
Дистилляция знаний и квантование
Через дистилляцию знаний более маленькие модели учатся у больших моделей, а точность в моделях ViT снижается через квантование для уменьшения использования памяти и вычислительной сложности, сохраняя точность.
Заключение
Исследование по эффективным MLLMs решает критические препятствия для их более широкого использования, предлагая методы уменьшения потребления ресурсов и улучшения доступности.
«`




















