
Обучение большой сверточной нейронной сети для классификации изображений:
Практические решения и ценность:
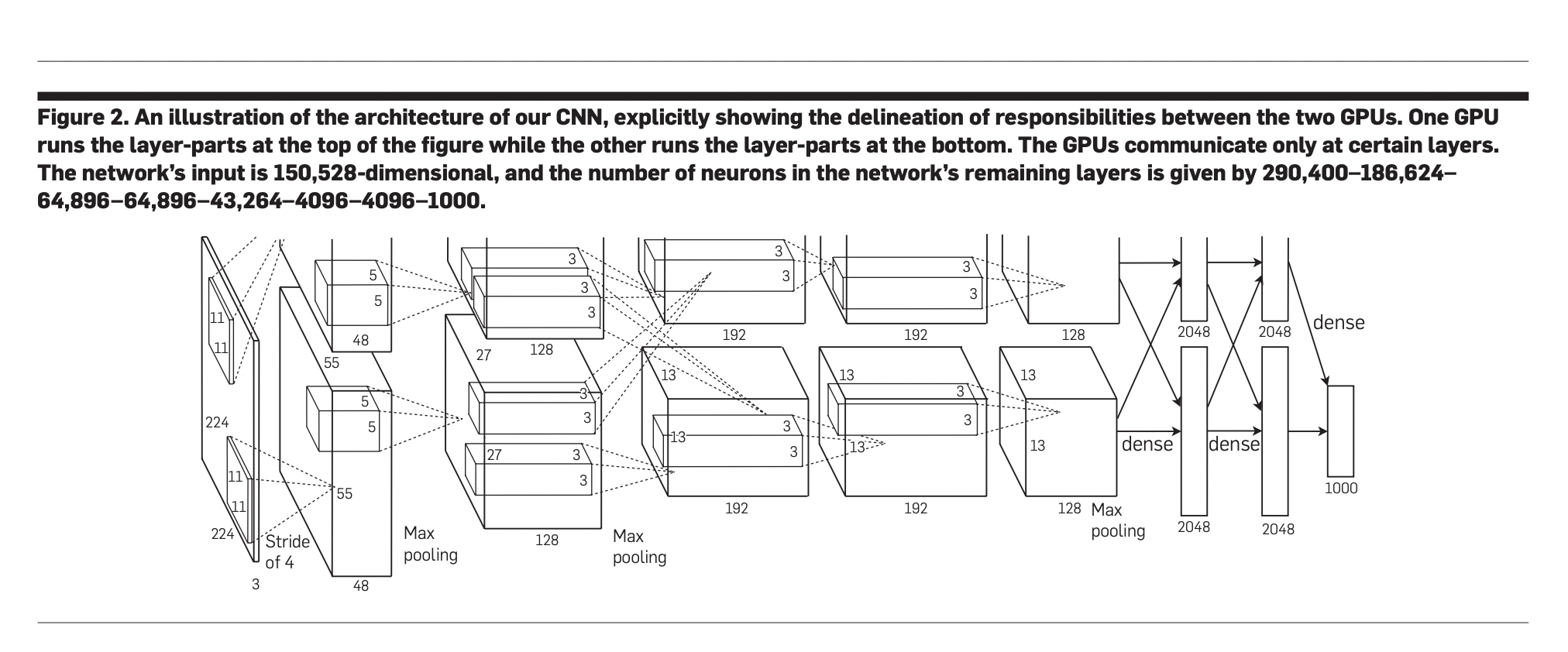
Исследователи разработали большую сверточную нейронную сеть для классификации 1.2 миллиона изображений высокого разрешения из конкурса ImageNet LSVRC-2010, охватывая 1000 категорий. Модель с 60 миллионами параметров и 650 000 нейронов продемонстрировала впечатляющие результаты, с ошибками top-1 и top-5 на уровне 37,5% и 17,0%, соответственно, значительно превосходя предыдущие методы. Архитектура включает пять сверточных слоев и три полностью связанных слоя, завершаясь 1000-путевым softmax. Ключевые инновации, такие как использование ненасыщающих нейронов и применение dropout для предотвращения переобучения, позволили эффективное обучение на GPU. Производительность сверточной нейронной сети улучшилась на ILSVRC-2012, достигнув ошибки top-5 на уровне 15,3%, по сравнению с 26,2% следующей лучшей модели.
Набор данных и архитектура сети:
Практические решения и ценность:
Исследователи использовали ImageNet, обширный набор данных из более чем 15 миллионов изображений высокого разрешения в 22 000 категориях, собранных с веб-сайтов и помеченных через Amazon Mechanical Turk. Для челленджа первого визуального распознавания крупного масштаба ImageNet (ILSVRC), начавшегося в 2010 году в рамках Pascal Visual Object Challenge, они сосредоточились на поднаборе ImageNet, содержащем около 1,2 миллиона обучающих изображений, 50 000 проверочных изображений и 150 000 тестовых изображений равномерно распределенных по 1000 категориям. Для обеспечения одинаковых размеров входных данных для своей сверточной нейронной сети все фотографии были масштабированы до 256 × 256 пикселей, изменив масштаб более короткой стороны до 256 и центрально обрезав изображение. Единственный дополнительный предварительный этап состоял в вычитании средней активности пикселей из каждого изображения, позволяя сети эффективно обучаться на сырых значениях RGB.
Уменьшение переобучения в нейронных сетях:
Практические решения и ценность:
Сеть, содержащая 60 миллионов параметров, сталкивается с переобучением из-за недостаточных ограничений обучающих данных. Для решения этой проблемы исследователи применяют две ключевые техники. Во-первых, аугментация данных искусственно увеличивает набор данных путем трансформации изображений, отражений и изменения интенсивности RGB с использованием PCA. Этот метод помогает снизить ошибки top-1 более чем на 1%. Во-вторых, используется dropout в полностью связанных слоях, случайно деактивируя нейроны во время обучения, чтобы предотвратить коадаптацию и улучшить устойчивость функций. Dropout увеличивает количество итераций обучения, но является ключевым при уменьшении переобучения без увеличения вычислительных затрат.
Результаты на соревнованиях ILSVRC:
Практические решения и ценность:
Модель CNN достигла ошибок top-1 и top-5 на уровне 37,5% и 17,0% на наборе данных ILSVRC-2010, превзойдя предыдущие методы, такие как разреженное кодирование (47,1% и 28,2%). В соревновании ILSVRC-2012 модель достигла ошибки валидации top-5 на уровне 18,2%, которая улучшилась до 16,4%, когда предсказания от пяти CNN были усреднены. Кроме того, предварительное обучение на наборе данных ImageNet Fall 2011, за которым следовало донастройка, снизило ошибку до 15,3%. Эти результаты значительно превзошли предыдущие методы, использующие плотные признаки, которые сообщали об ошибке тестирования top-5 на уровне 26,2%.




















