
«`html
Генеративный искусственный интеллект (AI)
Генеративный искусственный интеллект (AI) фокусируется на создании систем, способных создавать тексты, похожие на человеческие, и решать сложные задачи рассуждения. Эти модели являются важными в различных сферах, включая обработку естественного языка. Их основная функция — предсказывать последующие слова в последовательности, генерировать связный текст и даже решать логические и математические проблемы. Однако, несмотря на их впечатляющие возможности, генеративным моделям искусственного интеллекта часто необходима помощь для обеспечения точности и надежности их результатов, что особенно проблематично в задачах рассуждения, где одна ошибка может аннулировать всё решение.
Существующие методы решения проблемы
Для улучшения точности и надежности этих систем искусственного интеллекта существуют методы, включающие дискриминативные модели наград (RMs), которые классифицируют потенциальные ответы как правильные или неправильные на основе присвоенных им оценок. Однако эти модели должны полностью использовать генеративные способности больших языковых моделей (LLMs). Другим распространенным подходом является метод LLM-как-судья, где предварительно обученные языковые модели оценивают правильность решений. Хотя этот метод использует генеративные способности LLM, он часто не может сравниться с производительностью более специализированных проверяющих, особенно в задачах рассуждения, требующих тонкого суждения.
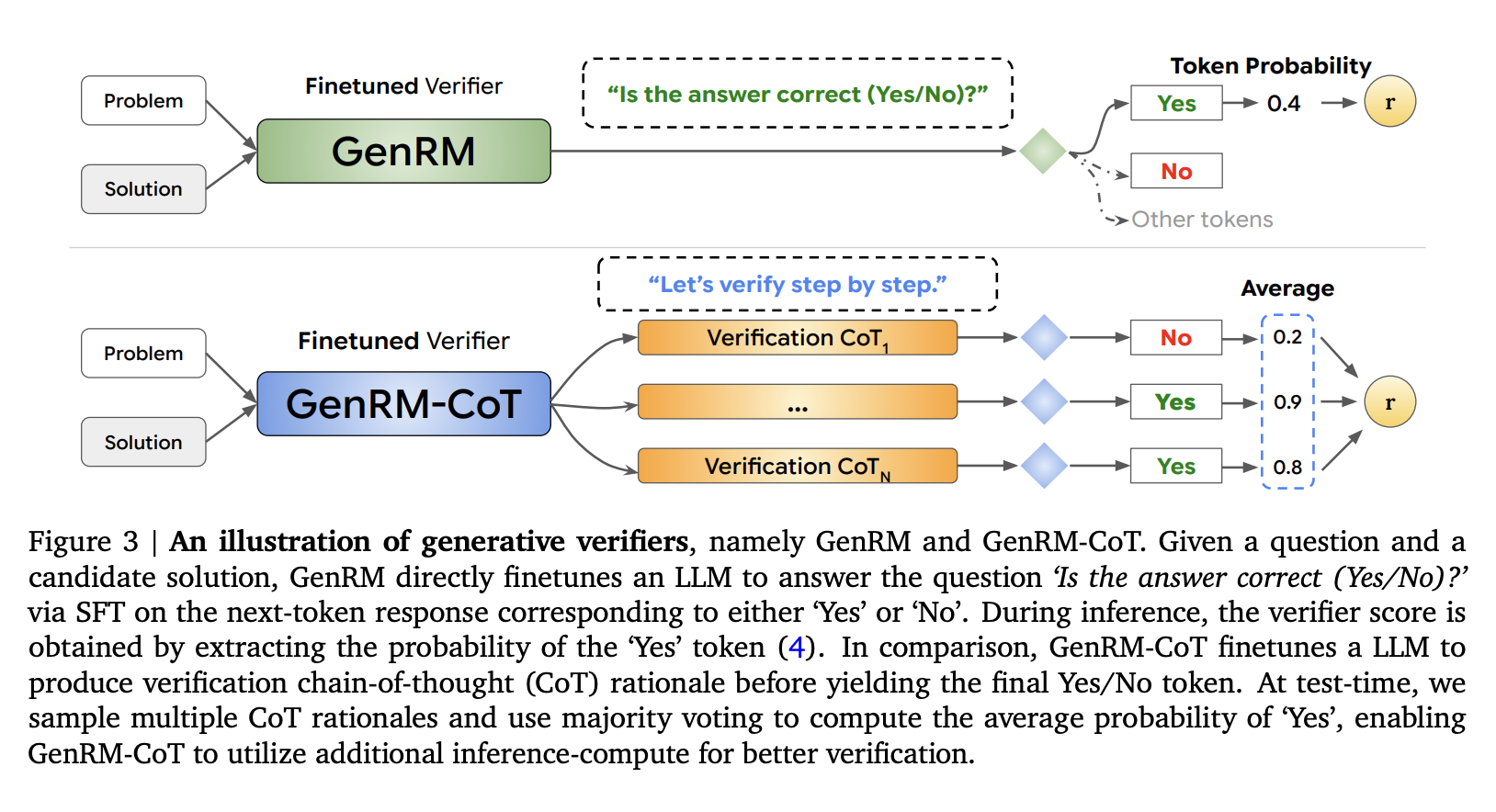
Новый подход от Google DeepMind Researchers — GenRM
Исследователи из Google DeepMind, Университета Торонто, MILA и UCLA представили новый подход, называемый Генеративное Моделирование Наград (GenRM). Этот метод переопределяет процесс верификации, представляя его как задачу предсказания следующего токена, фундаментальную способность LLMs. В отличие от традиционных дискриминативных RMs, GenRM интегрирует сильные стороны генерации текста LLMs в процесс верификации, позволяя модели генерировать и оценивать потенциальные решения одновременно. Этот подход также поддерживает рассуждение «цепочка мыслей» (CoT), где модель генерирует промежуточные шаги рассуждения перед принятием окончательного решения. Таким образом, метод GenRM не только оценивает правильность решений, но и улучшает общий процесс рассуждения, позволяя более детальную и структурированную оценку.
Применение методики GenRM
Методика GenRM использует унифицированный подход к обучению, объединяя генерацию решений и верификацию. Это достигается путем обучения модели предсказывать правильность решения через предсказание следующего токена, технику, которая использует врожденные генеративные способности LLMs. На практике модель генерирует промежуточные шаги рассуждения — CoT рационалы, которые затем используются для верификации окончательного решения. Этот процесс интегрируется существующими техниками обучения искусственного интеллекта, позволяя одновременно улучшать возможности генерации и верификации. Кроме того, модель GenRM получает дополнительные вычисления во время вывода, такие как мажоритарное голосование, агрегирующее несколько путей рассуждения для получения наиболее точного решения.
Преимущества и результаты
Производительность модели GenRM, особенно в сочетании с рассуждением CoT, значительно превосходит традиционные методы верификации. В серии строгих тестов, включая задачи, связанные с математикой начальной школы и решением алгоритмических задач, модель GenRM продемонстрировала значительное улучшение точности. Исследователи сообщили о увеличении процента правильно решенных задач на 16% — 64% по сравнению с дискриминативными RMs и методами LLM-как-судья. Например, при проверке результатов модели Gemini 1.0 Pro, подход GenRM улучшил процент успешности решения задач с 73% до 92,8%. Этот значительный прирост производительности подчеркивает способность модели устранять ошибки, которые стандартные верификаторы часто упускают, особенно в сложных ситуациях рассуждения. Кроме того, исследователи отметили, что модель GenRM эффективно масштабируется при увеличении размера набора данных и мощности модели, что дополнительно улучшает ее применимость в различных задачах рассуждения.
Заключение
Введение методики GenRM исследователями из Google DeepMind является значительным прорывом в области генеративного искусственного интеллекта, особенно в решении проблем верификации, связанных с задачами рассуждения. Модель GenRM предлагает более надежный и точный подход к решению сложных проблем, объединяя генерацию решений и верификацию в один процесс. Этот метод улучшает точность решений, сгенерированных искусственным интеллектом, и улучшает общий процесс рассуждения, делая его ценным инструментом для будущих применений искусственного интеллекта в различных областях. По мере развития генеративного искусственного интеллекта методика GenRM предоставляет прочный фундамент для дальнейших исследований и разработок, особенно в областях, где точность и надежность имеют большое значение.
Проверьте Paper. Вся заслуга за это исследование принадлежит ученым проекта. Также, не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе LinkedIn. Если вам нравится наша работа, вам понравится наш newsletter.
Не забудьте присоединиться к нашему SubReddit 50k+ ML SubReddit
Вот рекомендованный вебинар от нашего спонсора: «Построение высокопроизводительных приложений искусственного интеллекта с помощью NVIDIA NIMs и Haystack»
«`


















