
Применение Arena Learning для пост-тренировки больших языковых моделей с помощью симулированных битв на основе ИИ для повышения эффективности и производительности в обработке естественного языка
Большие языковые модели (LLM) показали исключительные способности в понимании и генерации человеческого языка, внося значительный вклад в приложения, такие как разговорный ИИ. Чат-боты, работающие на основе LLM, могут вести натуралистические диалоги и предоставлять широкий спектр услуг.
Эффективность этих чат-ботов в значительной степени зависит от использования данных высокого качества для пост-тренировки, позволяющих им эффективно взаимодействовать с людьми.
Решение задачи
Основной вызов заключается в эффективной пост-тренировке LLM с использованием высококачественных инструкционных данных. Традиционные методы, включающие человеческие аннотации и оценки для обучения моделей, затратны и ограничены доступностью человеческих ресурсов.
Появилась необходимость в автоматизированном и масштабируемом подходе для непрерывного улучшения LLM. Исследователи решают эту проблему, предлагая новый метод, который устраняет ограничения ручных процессов и использует ИИ для повышения эффективности и эффективности пост-тренировки.
Практические преимущества
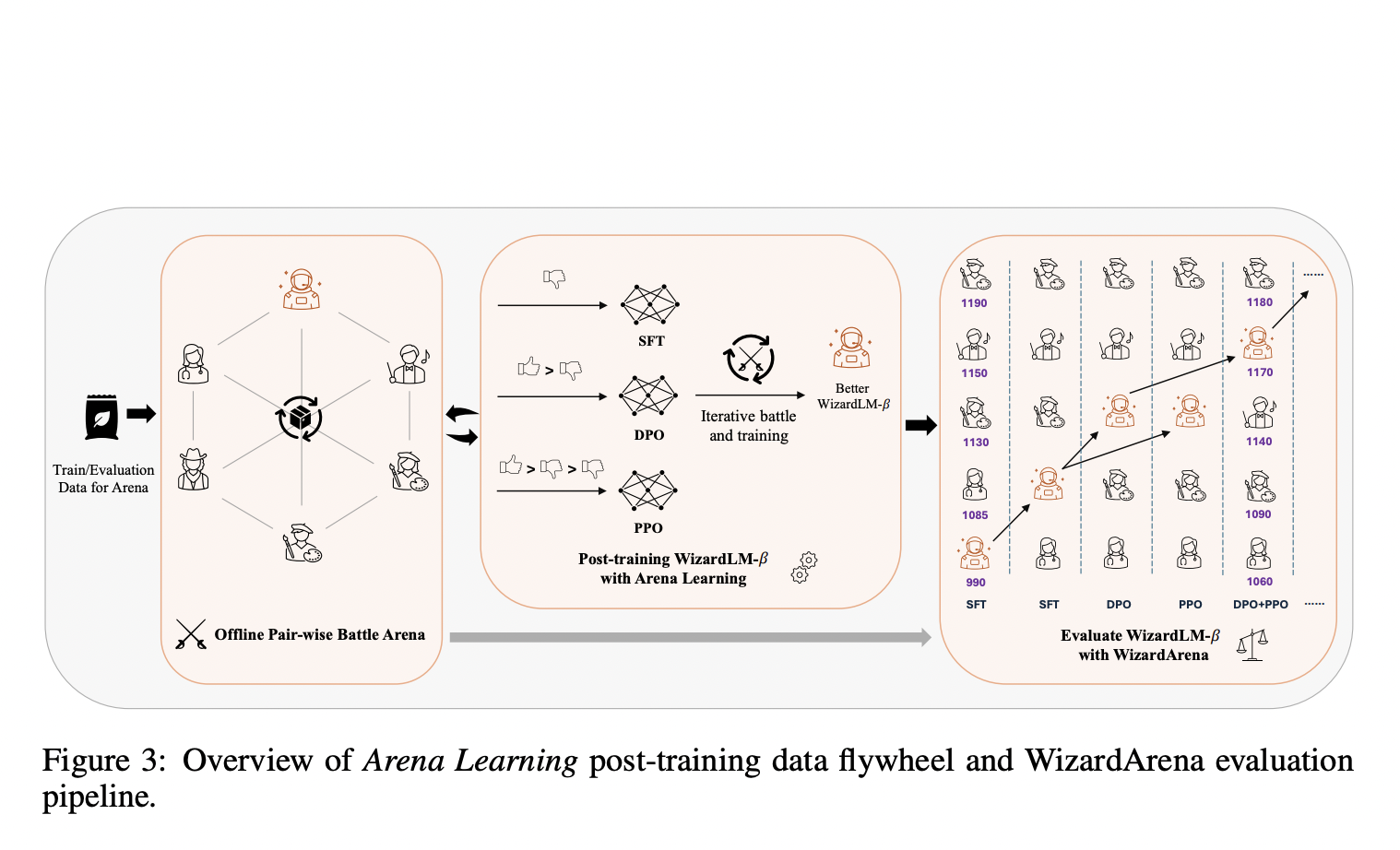
Метод Arena Learning позволяет улучшить модели LLM через непрерывное обучение с помощью симулированных битв и обучения с подкреплением. Это приводит к значительному улучшению производительности моделей, сокращению затрат и увеличению масштаба обучения.
Результаты
Экспериментальные результаты продемонстрировали значительное улучшение производительности моделей, обученных с использованием Arena Learning. Новый полностью автоматизированный пайплайн обучения и оценки на основе ИИ достиг 40-кратного увеличения эффективности по сравнению с LMSYS Chatbot Arena.
Заключение
Метод Arena Learning обеспечивает непрерывное и эффективное улучшение языковых моделей через симулированные битвы и итеративные процессы обучения. Этот подход сокращает зависимость от человеческих оценок и обеспечивает генерацию большого объема данных для обучения моделей. Исследование подчеркивает потенциал методов на основе ИИ для создания масштабируемых и эффективных решений для улучшения производительности LLM.
Подробнее ознакомьтесь с статьей. Вся благодарность за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему Telegram-каналу и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему SubReddit.
Источник изображения: Image Source