
Решения на основе искусственного интеллекта для улучшения работы с изображениями
Большие модели языка и их применение в обработке текста
Большие языковые модели (LLM) привлекли значительное внимание благодаря своим возможностям в обработке и генерации текста. Однако растущий спрос на обработку мультимодальных входных данных привел к развитию моделей языка видео. Эти модели объединяют преимущества LLM с кодировщиками изображений для создания больших моделей языка видения (LVLM). Несмотря на их многообещающие результаты, у LVLM стоит серьезная задача в получении качественных данных для настройки, так как получение контента, курируемого людьми в масштабе, часто является чрезмерно дорогостоящим, особенно для мультимодальных данных. Поэтому существует настоятельная необходимость в эффективных методах получения данных для настройки, чтобы улучшить LVLM и расширить их возможности.
Новые методы обучения на изображениях для LVLM
Недавние достижения в области моделей языка и видения были обусловлены интеграцией открытых LLM с инновационными кодировщиками изображений, что привело к разработке LVLM. Примеры включают в себя LLaVA, который объединяет видео-кодировщик CLIP с моделью Vicuna LLM, а также другие модели, такие как LLaMA-Adapter-V2, Qwen-VL и InternVL. Однако они часто зависят от дорогостоящих данных, курируемых людьми или созданных ИИ для настройки. Недавние исследования решают эту проблему, изучая техники настройки выравнивания, такие как прямая оптимизация политики (DPO) и итеративная настройка предпочтений. Однако применение этих методов для LVLM ограничено, с первоначальными попытками, сосредоточенными на данных, помеченных людьми или сгенерированных GPT-4 для настройки.
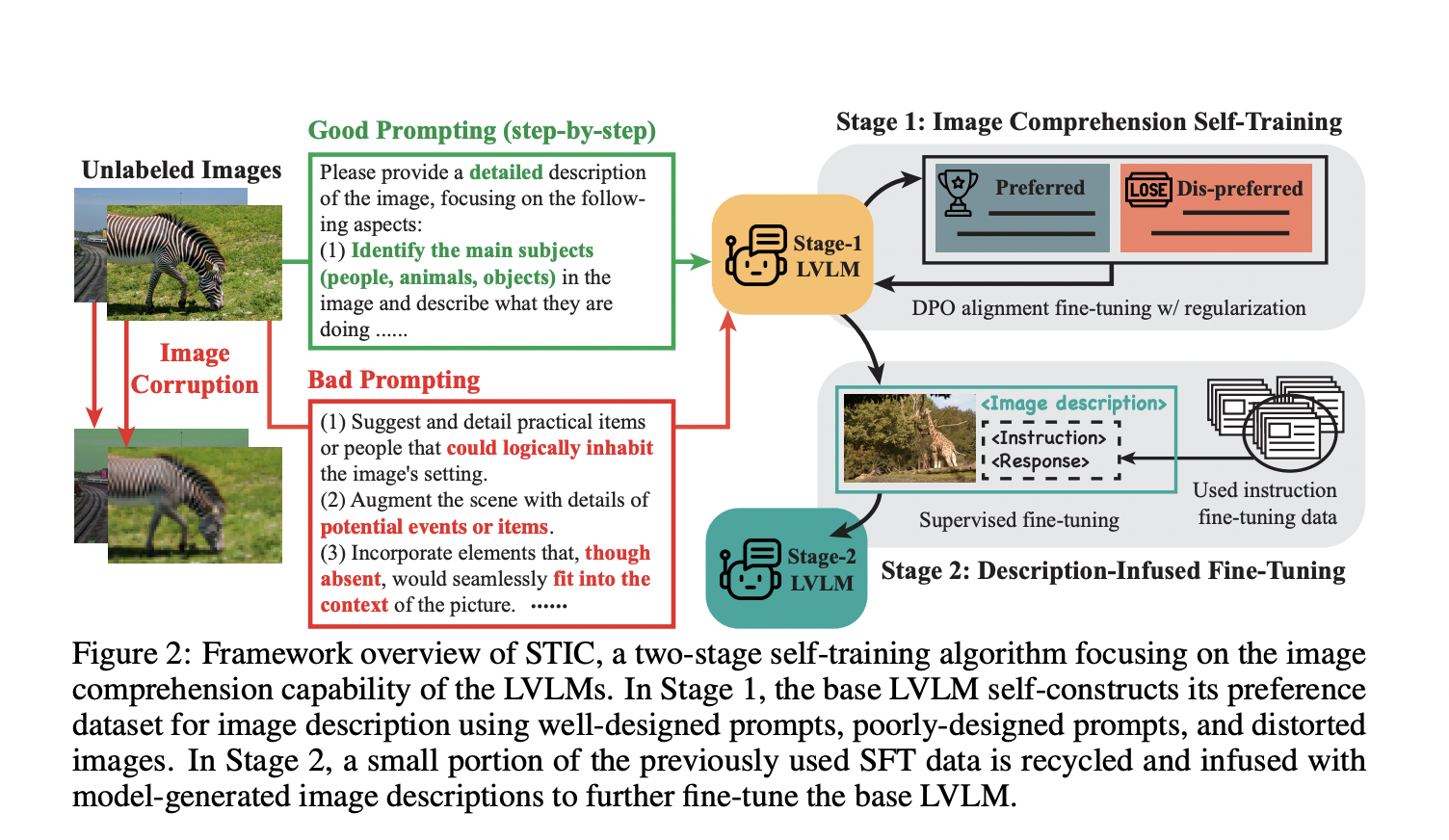
Метод самообучения по пониманию изображений (STIC)
Исследователи из UCLA, UC Berkeley и Стэнфордского университета представили подход, названный Self-Training on Image Comprehension (STIC). Этот метод акцентируется на самообучении специально для понимания изображений в LVLM и самостоятельно создает набор данных предпочтений для описаний изображений, используя немаркированные изображения. Он генерирует предпочтительные ответы через пошаговый запрос и непредпочтительные ответы из искаженных изображений или вводных данных. STIC повторно использует небольшую часть существующих данных настройки инструкций и добавляет самостоятельно созданные описания изображений к запросам для улучшения рассуждений на основе извлеченной визуальной информации.


















