
«`html
Эффективное обучение больших языковых моделей
Проблема и практическое решение
Большие языковые модели (LLM) становятся все более важными в обработке естественного языка, так как они могут выполнять широкий спектр задач с высокой точностью. Однако их настройка требует значительных вычислительных ресурсов и памяти.
Существующие методы, такие как PEFT, LoRA, Parallel Adapter, Switch Transformers и StableMoE, а также модели QLoRA и методы CPU-offload и LST, предлагают различные подходы к оптимизации использования памяти и вычислительных ресурсов.
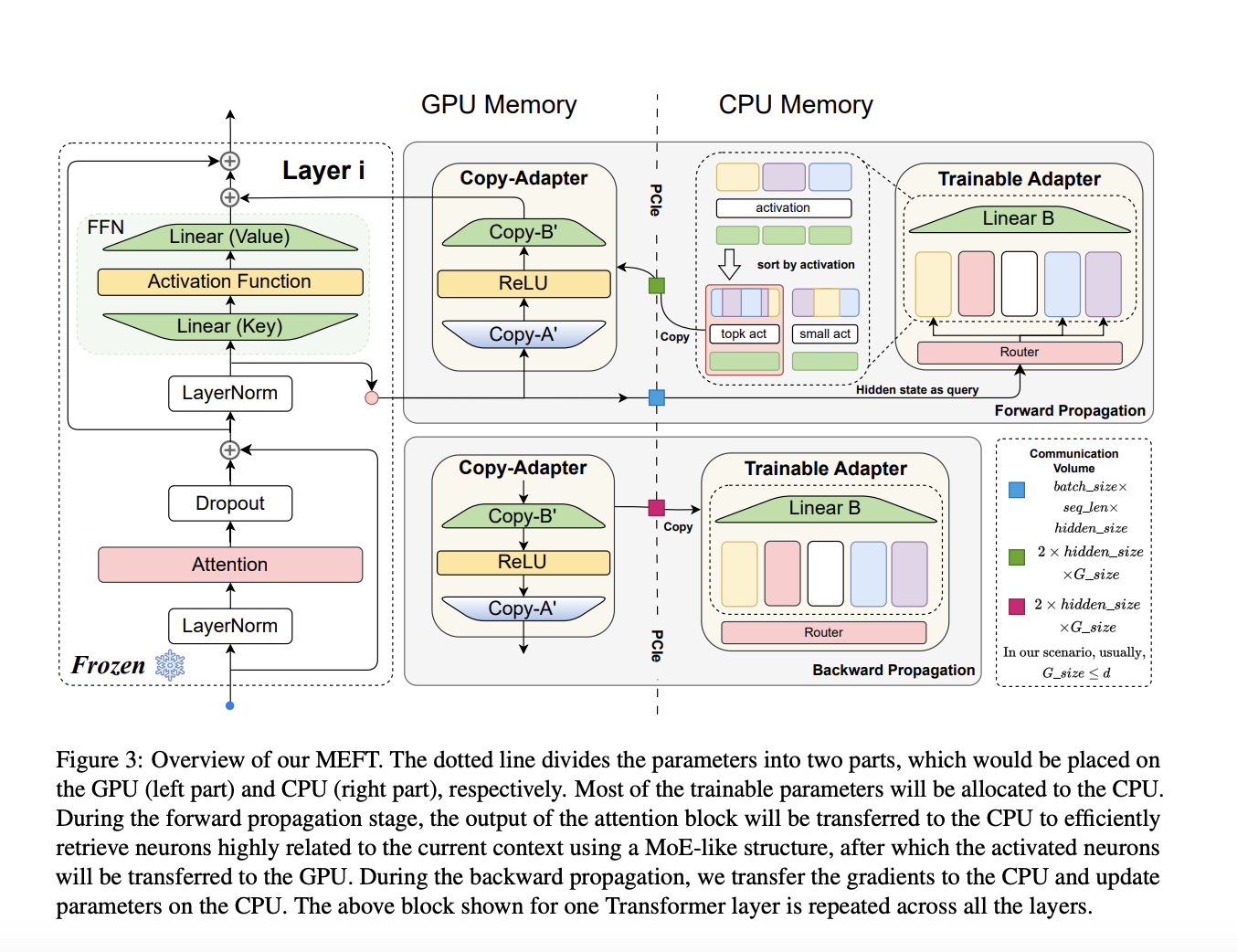
Исследователи из нескольких университетов представили метод MEFT, который позволяет существенно сократить использование памяти GPU при сохранении высокой производительности. MEFT был протестирован на нескольких моделях и наборах данных, показав значительное снижение использования памяти и сравнимые результаты с полной настройкой моделей.
Значимость и применение
MEFT представляет собой эффективное решение для ресурсоемкой задачи настройки больших языковых моделей. Его способность уменьшать использование памяти и вычислительных ресурсов делает его эффективным методом для настройки LLM при ограниченных ресурсах. Данное инновационное решение адресует критическую проблему масштабируемости настройки моделей, предоставляя более эффективный и масштабируемый подход.
«`



















