
«`html
Улучшение эффективности и производительности многозадачного обучения с подкреплением с помощью обучения политике на основе больших мировых моделей
Решения на основе исследования
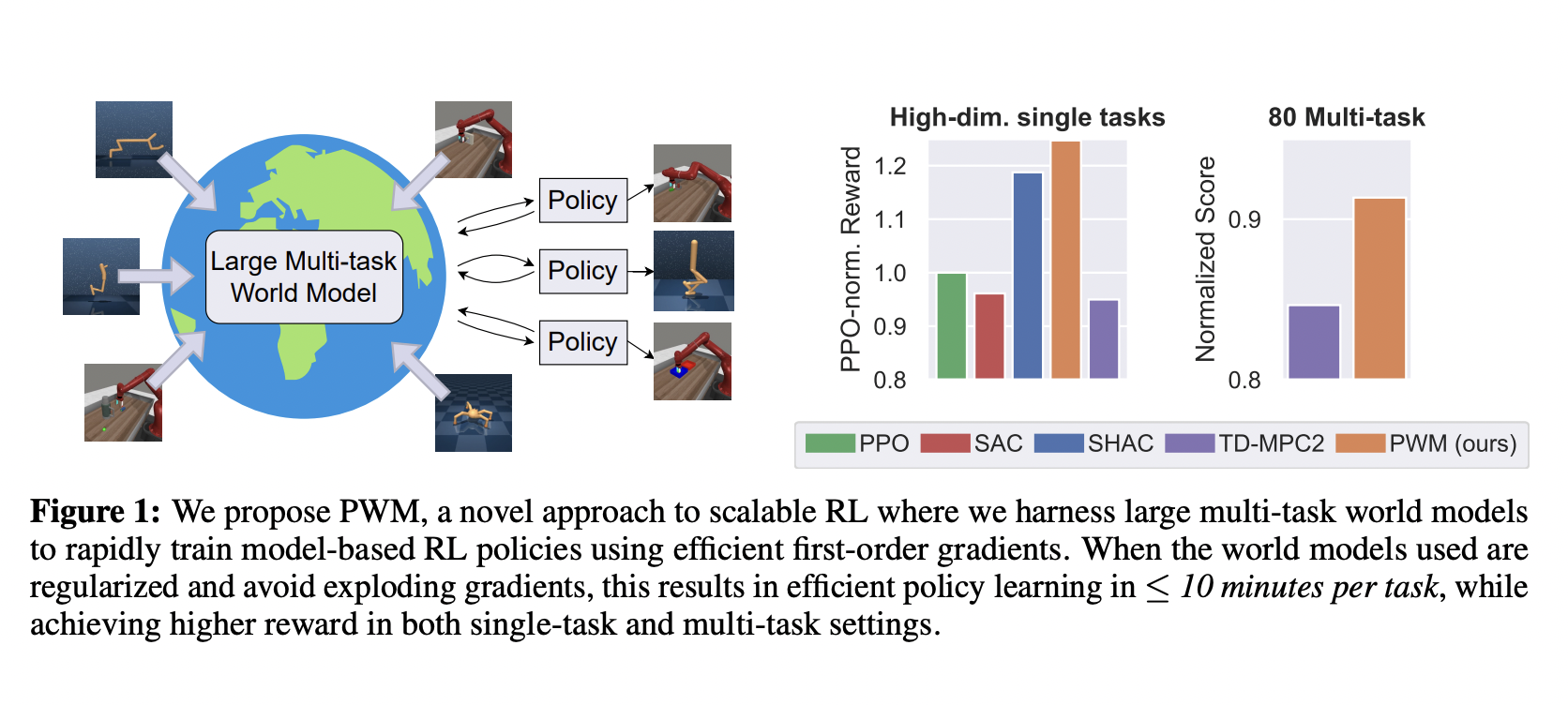
Исследование представляет инновационный алгоритм обучения политике на основе моделей среды, который позволяет решать задачи с до 152 измерениями действий. Этот подход превосходит существующие методы, достигая до 27% более высоких наград без дорогостоящего онлайн-планирования. Он демонстрирует, что эффективная оптимизация первого порядка приводит к лучшим политикам и более быстрому обучению по сравнению с традиционными методами нулевого порядка.
Практические применения
Исследование фокусируется на улучшении контроля в различных средах, таких как Hopper, Ant, Anymal, Humanoid и muscle-actuated Humanoid. Результаты показали, что предложенный метод достигает более высоких наград и более плавных ландшафтов оптимизации по сравнению с существующими методами. Также было выявлено, что он обладает устойчивостью к жестким контактным моделям и обладает более высокой эффективностью выборки.
Развитие исследования
Не смотря на свои преимущества, метод сильно зависит от обширных предварительно существующих данных для обучения мировых моделей, что ограничивает его применимость в сценариях с недостаточным количеством данных. Кроме того, хотя метод обеспечивает эффективное обучение политик, он требует повторного обучения для каждой новой задачи, что представляет вызовы для быстрой адаптации.
Ссылки и контакты
Подробнее о исследовании можно узнать на странице GitHub. Для получения дополнительной информации и консультаций по внедрению ИИ обращайтесь на наш Telegram-канал. Следите за новостями в нашем Телеграм-канале itinainews или в Twitter @itinairu45358.
«`




















