
«`html
Решение для сжатия крупных языковых моделей: Efficient Quantization-Aware Training (EfficientQAT)
Эффективное обучение с учетом квантования (EfficientQAT) представляет собой новую технику машинного обучения для сжатия крупных языковых моделей (LLMs), таких как модели глубокого обучения на базе трансформеров. Этот метод решает проблему значительных требований к памяти и вычислительным ресурсам при обучении моделей искусственного интеллекта (ИИ).
Основные преимущества EfficientQAT:
- Снижение требований к памяти и вычислительным ресурсам при обучении моделей
- Улучшение эффективности и производительности квантованных моделей
- Быстрота сходимости и возможность эффективной настройки моделей для конкретных задач
Практическое применение EfficientQAT:
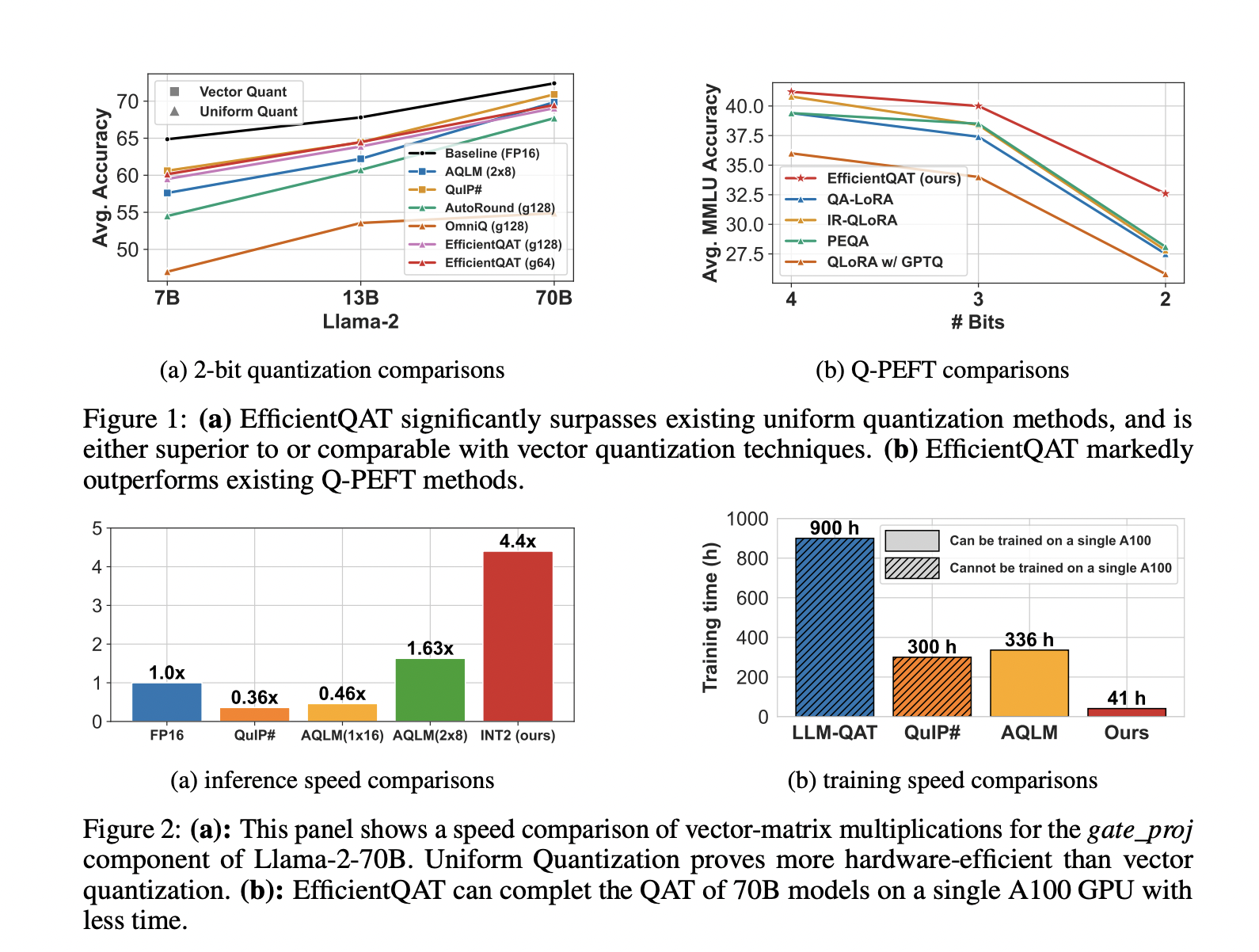
Метод EfficientQAT позволяет сжимать модели с минимальной потерей точности. Например, он достигает квантования модели Llama-2-70B до 2 бит на одном графическом процессоре A100-80GB за 41 час, с потерей точности менее 3% по сравнению с моделью полной точности. Также он превосходит существующие методы квантования в сценариях с низкими значениями бит, обеспечивая более эффективное использование аппаратных ресурсов.
Применение в бизнесе:
Если вы хотите внедрить искусственный интеллект в ваш бизнес, EfficientQAT предоставляет практическую технику для сжатия крупных языковых моделей, обеспечивая оптимальное использование вычислительных ресурсов и памяти. Это открывает возможности для использования больших языковых моделей в условиях ограниченных ресурсов.
Познакомьтесь с исследованием и GitHub. Вся заслуга за это исследование принадлежит его авторам.
Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вас заинтересовала наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу на SubReddit.
«`





















