
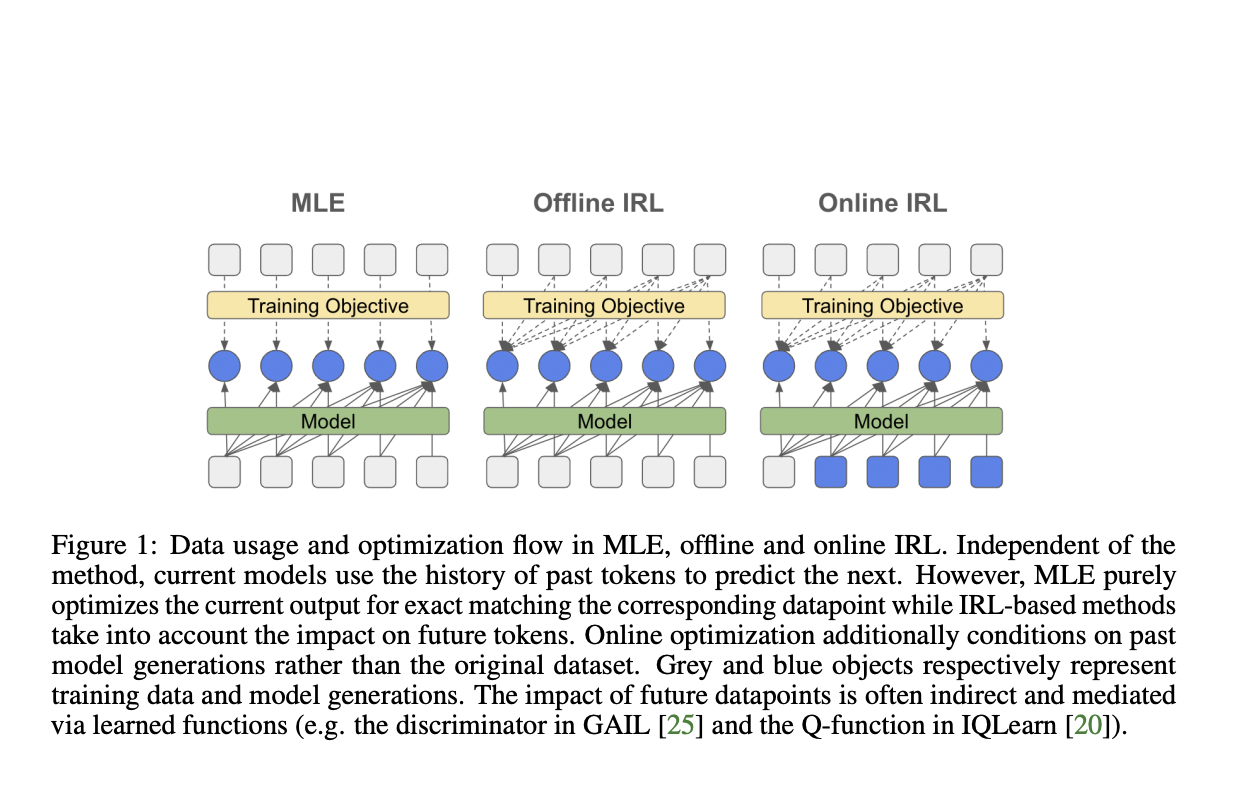
«`html
Использование больших языковых моделей в искусственном интеллекте
Большие языковые модели (LLM) привлекли значительное внимание в области искусственного интеллекта, в основном благодаря их способности имитировать человеческие знания на основе обширных наборов данных. Текущие методики обучения этих моделей тесно связаны с обучением по имитации, в частности, предсказанием следующего токена с использованием оценки максимального правдоподобия (MLE) во время предварительного обучения и надзорной донастройки. Однако этот подход сталкивается с несколькими проблемами, включая ошибки в авторегрессионных моделях, предвзятость в экспозиции и сдвиги распределения во время итеративного применения модели. По мере развития области возникает растущая потребность в решении этих проблем и разработке более эффективных методов обучения и выравнивания LLM с предпочтениями и намерениями человека.
Решение вызовов обучения языковых моделей
Существующие попытки решить вызовы обучения языковых моделей в основном сосредоточены на двух основных подходах: клонировании поведения (BC) и обратном обучении поощрению (IRL). BC, аналогично надзорной донастройке через MLE, напрямую имитирует экспертные демонстрации, но страдает от ошибок и требует обширного охвата данных. IRL, с другой стороны, совместно выводит политику и функцию вознаграждения, потенциально преодолевая ограничения BC с использованием дополнительных взаимодействий с окружающей средой. Недавние методы IRL включают игровые теоретические подходы, регуляризацию энтропии и различные методы оптимизации для улучшения стабильности и масштабируемости. В контексте языкового моделирования некоторые исследователи исследовали методы адверсарного обучения, такие как SeqGAN, в качестве альтернатив MLE. Однако эти подходы показали ограниченный успех, работая эффективно только в определенных температурных режимах. Несмотря на эти усилия, область продолжает искать более надежные и масштабируемые решения для обучения и выравнивания больших языковых моделей.
Практические результаты исследования DeepMind
Исследователи DeepMind предлагают глубокое изучение оптимизации на основе обратного обучения поощрению, с особым вниманием к перспективе соответствия распределения в IRL для донастройки больших языковых моделей. Этот подход направлен на предоставление эффективной альтернативы стандартному MLE. Исследование охватывает как адверсарные, так и неадверсарные методы, а также офлайн и онлайн техники. Ключевым новшеством является расширение обратного мягкого Q-обучения для установления принципиальной связи с классическим клонированием поведения или MLE. Исследование оценивает модели от 250M до 3B параметров, включая архитектуры T5 с кодировщиком-декодером и PaLM2 только с декодером. Исследование стремится продемонстрировать преимущества IRL перед клонированием поведения в обучении по имитации для языковых моделей, исследуя производительность задач и разнообразие генерации.
Результаты исследования
Исследователи провели обширные эксперименты для оценки эффективности методов IRL по сравнению с MLE для донастройки больших языковых моделей. Их результаты демонстрируют несколько ключевых выводов:
- Улучшение производительности: методы IRL, особенно IQLearn, показали небольшие, но заметные улучшения производительности задач на различных бенчмарках, включая XSUM, GSM8k, TLDR и WMT22. Эти улучшения были особенно заметны для математических и логических задач.
- Повышение разнообразия: IQLearn последовательно производил более разнообразные генерации моделей по сравнению с MLE, что указывает на лучший баланс между производительностью задач и разнообразием вывода.
- Масштабируемость модели: Преимущества методов IRL были замечены для различных размеров моделей и архитектур, включая модели T5 (base, large и xl) и PaLM2.
- Чувствительность к температуре: Для моделей PaLM2 IQLearn достиг лучшей производительности в режимах выборки с низкой температурой по всем протестированным задачам, что указывает на улучшенную стабильность качества генерации.
- Снижение зависимости от поиска лучших вариантов: IQLearn продемонстрировал способность снизить зависимость от поиска лучших вариантов во время вывода, сохраняя производительность и, возможно, обеспечивая выигрыши в вычислительной эффективности.
- Производительность GAIL: В то время как GAIL стабилизировался для моделей T5, его эффективная реализация для моделей PaLM2 оказалась сложной, что подчеркивает устойчивость подхода IQLearn.
Эти результаты свидетельствуют о том, что методы IRL, особенно IQLearn, представляют собой масштабируемую и эффективную альтернативу MLE для донастройки больших языковых моделей, предлагая улучшения как в производительности задач, так и в разнообразии генерации по ряду задач и архитектур моделей.
Применение в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Rethinking LLM Training: The Promise of Inverse Reinforcement Learning Techniques. Проанализируйте, как ИИ может изменить вашу работу, определите, где возможно применение автоматизации и подберите подходящее решение. Внедряйте ИИ решения постепенно, начиная с малых проектов и анализируя результаты.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358.
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru. Будущее уже здесь!
«`



















