«`html
Оптимизация KV-Cache для эффективного вывода крупных языковых моделей
Большие языковые модели (LLM) — это подмножество искусственного интеллекта, фокусирующееся на понимании и генерации человеческого языка. Эти модели используют сложные архитектуры для понимания и создания текста, что облегчает их применение в области обслуживания клиентов, создания контента и не только.
Основная проблема с LLM
Одной из основных проблем с LLM является их эффективность при обработке длинных текстов. Архитектура Transformer, которую они используют, имеет квадратичную временную сложность, что значительно увеличивает вычислительную нагрузку, особенно при работе с длинными последовательностями. Это создает значительное препятствие для достижения эффективной производительности, особенно при увеличении длины входных текстов.
Решение проблемы
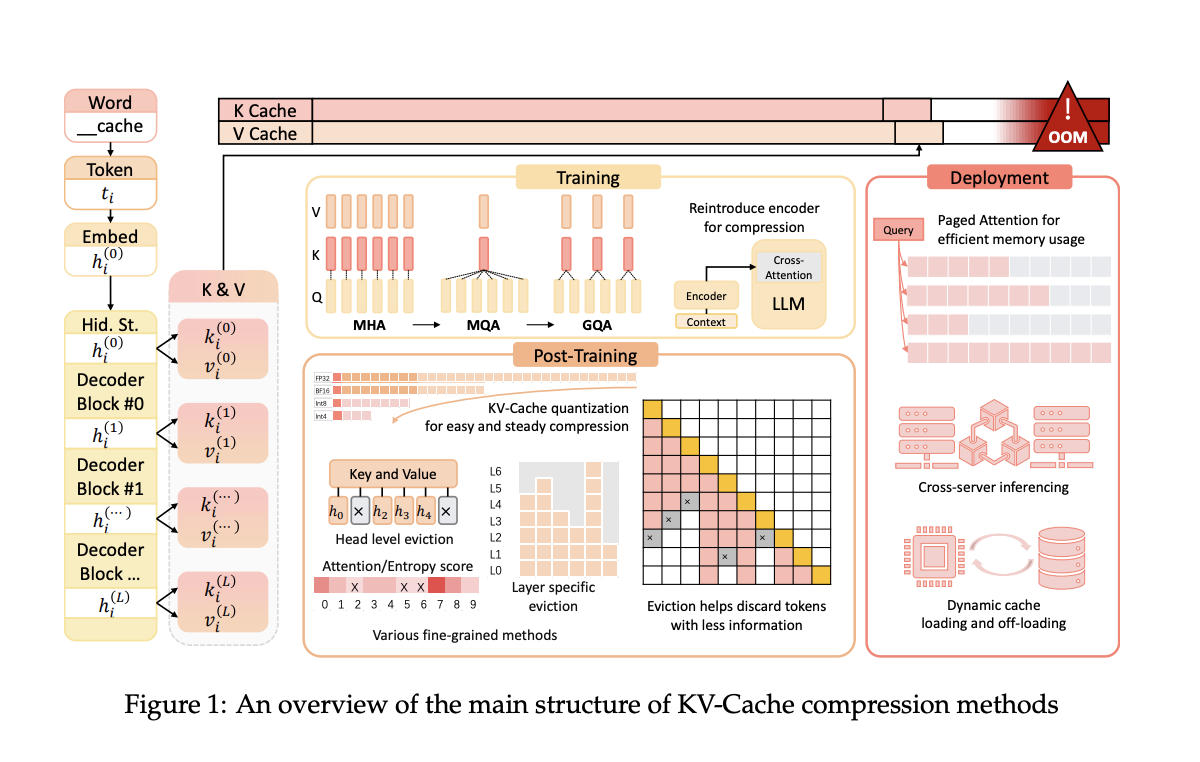
Исследователи предложили механизм KV-Cache для решения этой проблемы, который хранит ключи и значения, сгенерированные предыдущими токенами. Это позволяет снизить временную сложность с квадратичной до линейной. Однако использование KV-Cache увеличивает использование памяти GPU, что создает новое узкое место. Текущие методы направлены на балансировку этой компромиссной ситуации между вычислительной эффективностью и накладными расходами памяти, что делает оптимизацию использования KV-Cache крайне важной.
Предложенные методы
Исследовательская группа из Университета Ухань и Университета Шанхая представила несколько методов сжатия KV-Cache. Эти методы оптимизируют использование пространства KV-Cache во время предварительного обучения, развертывания и вывода LLM, с целью повышения эффективности без ущерба производительности. Их подход включает модификацию архитектуры модели во время предварительного обучения для уменьшения размера векторов ключей и значений до 75%. Это позволяет сохранить преимущества механизма внимания при существенном снижении требований к памяти.
Предложенные методы включают архитектурные изменения во время предварительного обучения, которые уменьшают размер сгенерированных векторов ключей и значений. Во время развертывания такие фреймворки, как Paged Attention и DistKV-LLM, распределяют KV-Cache по нескольким серверам для улучшения управления памятью. Методы пост-обучения включают динамические стратегии вытеснения и техники квантования, которые сжимают KV-Cache без существенной потери возможностей модели.
Практические результаты
Предложенные методы показали значительное улучшение эффективности памяти и скорости вывода. Например, метод GQA, используемый в популярных моделях, таких как LLaMA2-70B, достигает лучшего использования памяти за счет уменьшения размера KV-Cache при сохранении уровня производительности. Эти оптимизации демонстрируют потенциал более эффективной обработки более длинных контекстов. Конкретно, GQA снижает использование памяти до доли от того, что требуется традиционными методами, достигая 75% сокращения размера KV-Cache. Кроме того, модели, использующие Multi-Query Attention (MQA) и GQA, демонстрируют улучшенную пропускную способность и сниженную задержку, что является важными метриками для приложений в реальном времени.
Исследование предоставляет комплексные стратегии для оптимизации KV-Cache в LLM, решая проблему накладных расходов памяти. Путем внедрения этих методов LLM могут достичь более высокой эффективности и производительности, что открывает путь для более устойчивых и масштабируемых решений на основе ИИ. Результаты исследования из Университета Ухань и Университета Шанхая предлагают план для будущих усовершенствований, подчеркивая важность эффективного управления памятью в развитии технологии LLM. Эти стратегии не только устраняют текущие ограничения, но также открывают пути для изучения более сложных применений LLM в различных отраслях.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn. Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему сообществу в SubReddit.
Найдите предстоящие вебинары по ИИ здесь.
Этот пост был опубликован на сайте MarkTechPost.
Применение ИИ в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This AI Paper from China Introduces KV-Cache Optimization Techniques for Efficient Large Language Model Inference.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter itinairu45358.
Попробуйте AI Sales Bot здесь. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`




















