
Оптимизация Политики Управления Длиной: Повышение Моделей Рассуждений с Точным Контролем Вывода
Модели рассуждений могут значительно повысить свою эффективность, генерируя более длинные последовательности размышлений во время вывода. Однако основной проблемой является отсутствие контроля над длиной размышлений, что затрудняет эффективное распределение вычислительных ресурсов.
Проблемы с Длиной Вывода
Существующие подходы часто приводят к снижению производительности. Например, использование специальных токенов для регулирования длины вывода может привести к неоптимальным результатам. Модели рассуждений требуют балансировки между вычислительной эффективностью и точностью, что подчеркивает необходимость точного контроля длины.
Исследования и Решения
Прошлые исследования продемонстрировали, что увеличение вычислительных ресурсов во время вывода может улучшить производительность в сложных задачах рассуждений. Тем не менее, существующие методы не позволяют точно контролировать длину размышлений, что приводит к неэффективности. Новая методика управления длиной размышлений, представленная исследователями из Университета Карнеги-Меллона, решает эти проблемы.
Достижения Методики LCPO
LCPO (Length Controlled Policy Optimization) является методом, основанным на обучении с подкреплением, который улучшает модели рассуждений, обеспечивая точность и соблюдение заданных пользователем ограничений по длине. Модели, обученные с помощью LCPO, эффективно балансируют вычислительные затраты и производительность, адаптируя длину размышлений через ограничения в запросах.
Варианты Моделей
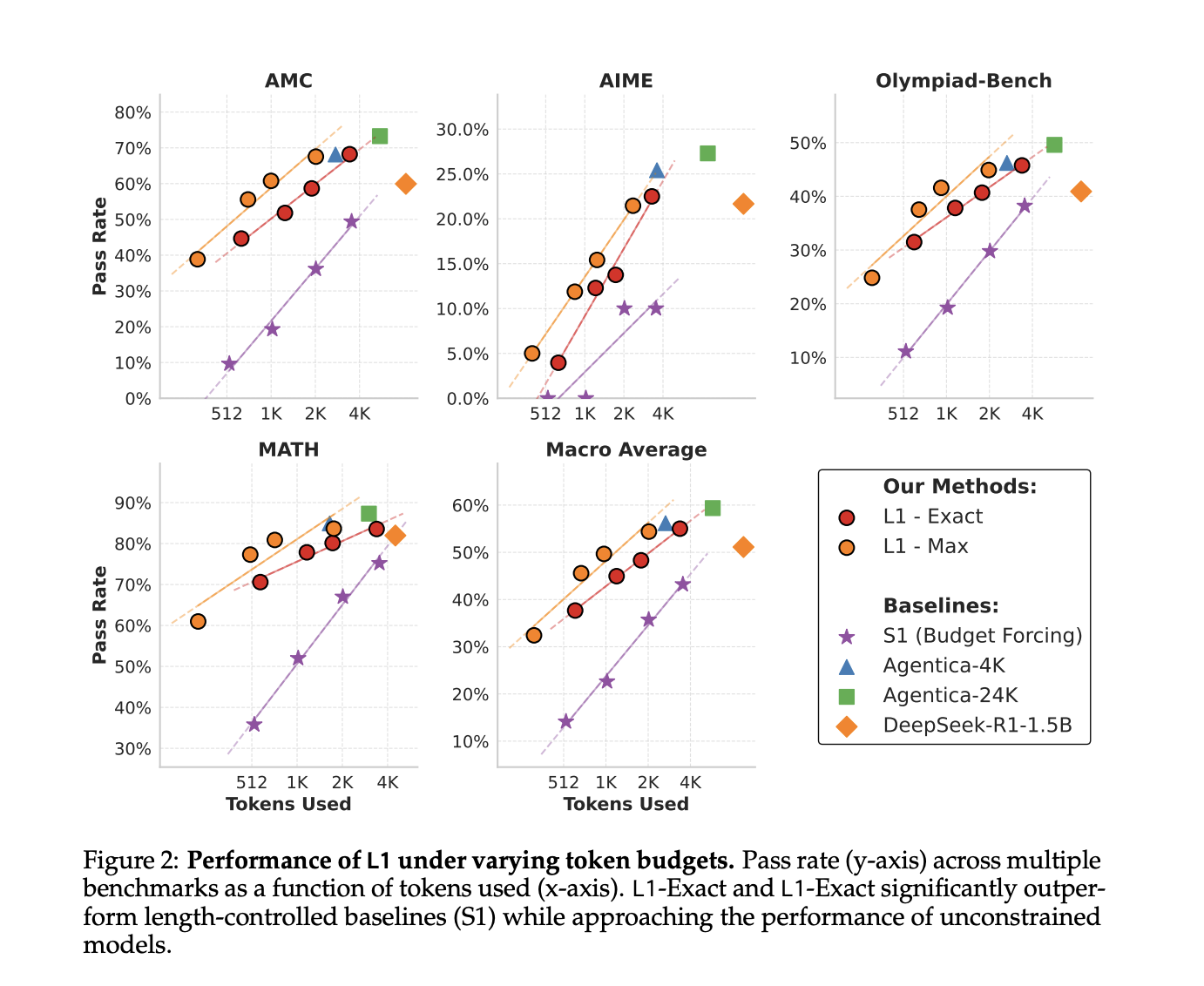
В результате были разработаны два варианта: L1-Exact, который точно соответствует заданной длине, и L1-Max, который сохраняет гибкость, оставаясь в рамках максимальной длины. Эти методы значительно повышают эффективность, оптимизируя производительность рассуждений при управлении вычислительными затратами.
Результаты Исследования
Модель L1 продемонстрировала превосходство в текстовой генерации с контролем длины на различных тестах, достигая 20-25% абсолютных и более 100% относительных приростов, эффективно адаптируя цепочки размышлений без обрезки. Она также хорошо обобщается на задачи вне домена и демонстрирует высокую точность соблюдения длины при решении математических задач.
Заключение
Методика LCPO позволяет точно контролировать длину цепочек рассуждений в языковых моделях, обучая модель L1 соблюдать заданные пользователем ограничения длины при оптимизации точности. Это решение эффективно уравновешивает вычислительные затраты и точность, предоставляя простые способы контроля длины через запросы.
Практические Рекомендации для Бизнеса
Исследуйте, как технологии искусственного интеллекта могут преобразовать ваш подход к работе:
- Находите процессы, которые можно автоматизировать.
- Определите важные показатели, чтобы убедиться, что ваши инвестиции в ИИ положительно влияют на бизнес.
- Выбирайте инструменты, которые соответствуют вашим потребностям и позволяют настроить их для достижения ваших целей.
- Начните с небольшого проекта, собирайте данные о его эффективности и постепенно расширяйте использование ИИ.
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Подписывайтесь на наш Telegram, чтобы быть в курсе последних новостей ИИ: t.me/itinai.



















