«`html
Модели ИЯ нового поколения: Оптимизация мыслительных процессов (TPO)
Большие языковые модели (LLMs) стали мощными инструментами, способными понимать и отвечать на запросы пользователей. Однако они часто дают ответы, не учитывая сложность задания. Это может привести к недостаткам в сложных задачах, требующих логического мышления. Поэтому исследователи работают над тем, чтобы LLMs могли думать перед тем, как отвечать.
Проблемы текущих моделей
LLMs часто не учитывают детали инструкций. Для простых задач это приемлемо, но при сложных заданиях они могут не справиться. Трудность заключается в том, чтобы научить модели генерировать и анализировать внутренние мысли перед выдачей финального ответа. Это традиционно требует много ресурсов и больших аннотированных данных.
Решение: Оптимизация предпочтений мыслей (TPO)
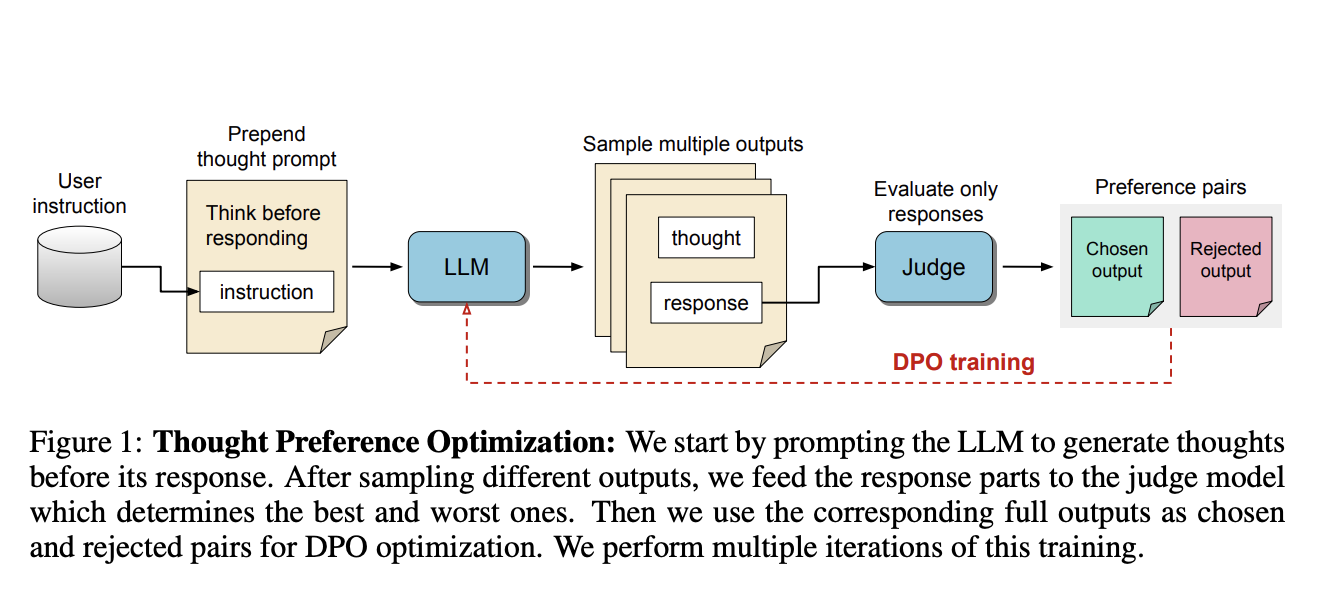
Исследователи из Meta FAIR, Университета Калифорнии и Нью-Йоркского университета разработали метод TPO. Это позволяет моделям Генерировать и улучшать внутренние мысли без дополнительных данных. Модель разделяет выходной результат на две части: процесс мышления и финальный ответ. Направляя модель на нужные мысли, мы можем оценивать и улучшать её способности.
Преимущества метода TPO
Метод TPO использует технику обучения с подкреплением, где модель улучшает качество ответов. Она генерирует мысли перед тем, как отвечать. Судейская модель оценивает ответы, что помогает в процессе итерации.
Результаты и достижения
TPO продемонстрировала рост эффективности моделей на тестах AlpacaEval и Arena-Hard, достигнув 52.5% и 37.3% соответственно. Это затрагивает не только логические задачи, но и маркетинг, креативные задачи и общие вопросы, что свидетельствует об универсальности метода.
Основные выводы из исследования
- TPO увеличила победные показатели LLMs на 52.5% и 37.3% на тестах AlpacaEval и Arena-Hard.
- Метод не требует аннотированных данных, что делает его эффективным и доступным.
- TPO улучшает креативные задачи и маркетинг.
- После нескольких итераций TPO модели продемонстрировали значительное улучшение.
Заключение
Оптимизация предпочтений мыслей (TPO) позволяет моделям мыслить перед ответами, что решает одну из главных проблем традиционных LLMs. Это откроет новые возможности для использования ИИ в самых разных областях.
«`




















