
«`html
Self-Play Preference Optimization (SPPO): Инновационный подход машинного обучения к настройке больших языковых моделей (LLM) отзывами от человека/ИИ
Большие языковые модели (LLM) продемонстрировали замечательные способности в генерации текста, ответах на вопросы и написании кода. Однако они сталкиваются с препятствиями, требующими высокой надежности, безопасности и этической соблюдения. Усиленное обучение на основе обратной связи от человека (RLHF), или предпочтительное обучение с подкреплением (PbRL), возникает как многообещающее решение. Этот фреймворк показал значительный успех в настройке LLM для соответствия предпочтениям человека, улучшая их полезность.
Основные аспекты
RLHF подвергается исследованиям, основанным на прямых вероятностях предпочтений, что лучше отражает предпочтения человека. Некоторые исследователи формулируют RLHF как поиск равновесий Нэша в играх с постоянной суммой, предлагая методы зеркального спуска и оптимизации предпочтений самопроигрывания (SPO). Прямая оптимизация Нэша (DNO) также была представлена на основе разрывов в выигрышной ставке, однако ее практическая реализация все еще зависит от итеративных фреймворков DPO.
Практическое применение
Ученые из Университета Калифорнии в Лос-Анджелесе и Карнеги Меллон представляют надежный фреймворк самопроигрыша, Self-Play Preference Optimization (SPPO), для выравнивания языковой модели, решая проблемы RLHF. Он предлагает доказанные гарантии для решения игр с постоянной суммой для двух игроков и масштабируемость для больших языковых моделей. В формулировании RLHF как такой игры цель заключается в выявлении политики равновесия Нэша, обеспечивая постоянно предпочтительные ответы. Они предлагают адаптивный алгоритм на основе мультипликативных весов, используя механизм самопроигрыша, где политика настраивается на синтетических данных, аннотированных моделью предпочтений.
Ценность и практическая польза
Фреймворк самопроигрыша направлен на эффективное решение игр с постоянной суммой для двух игроков масштабных языковых моделей. Он принимает итеративный фреймворк на основе обновлений мультипликативных весов и механизма самопроигрыша. Алгоритм асимптотически сходится к оптимальной политике, выявляя равновесие Нэша. Теоретический анализ гарантирует сходимость, предоставляя доказанные гарантии. По сравнению с существующими методами, такими как DPO и IPO, SPPO демонстрирует улучшенную сходимость и эффективно решает проблемы разреженности данных.
Результаты исследований
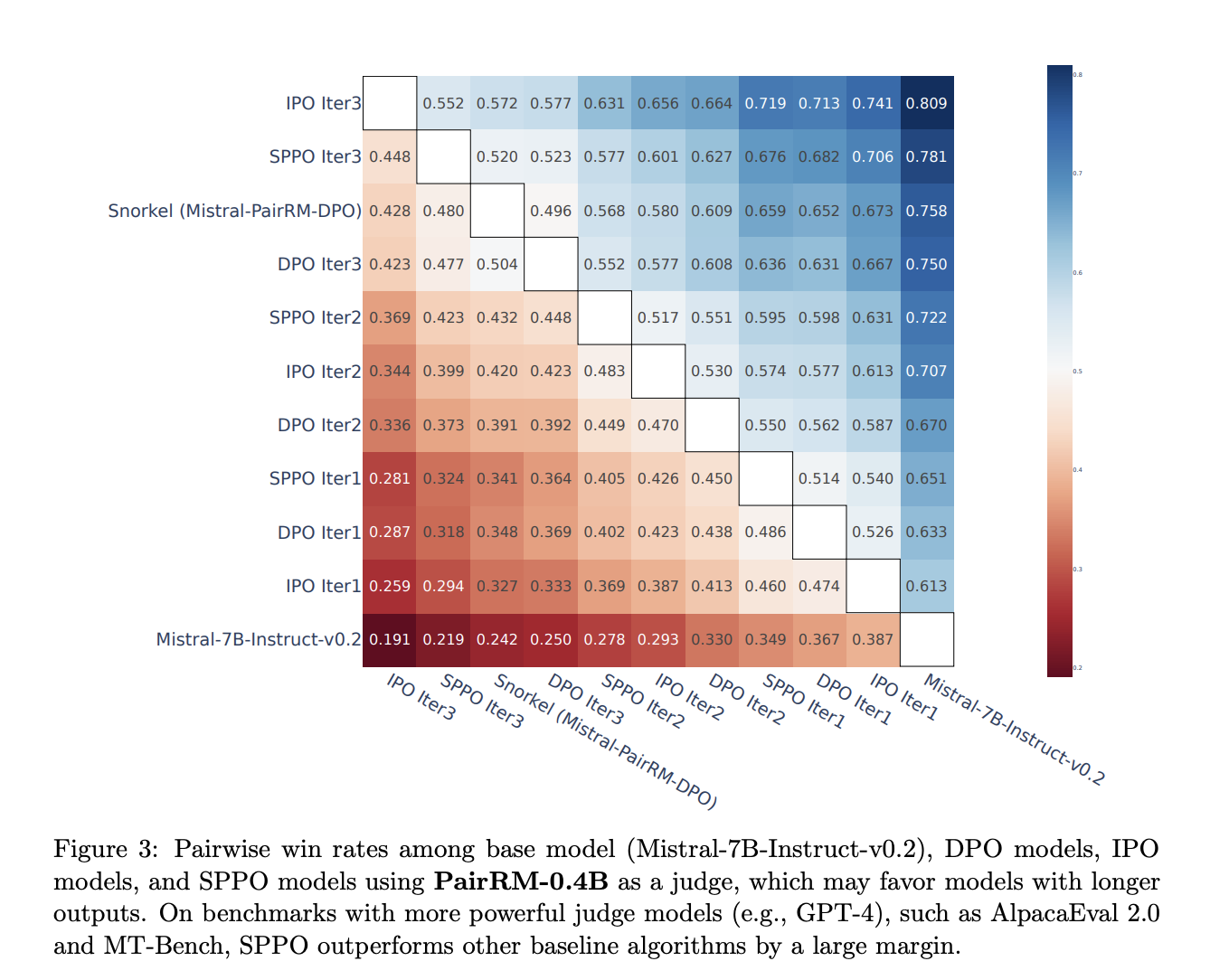
Исследователи оценивают модели с использованием GPT-4 для автоматической оценки, представляя результаты на AlpacaEval 2.0 и MT-Bench. Модели SPPO последовательно улучшаются на протяжении итераций, причем SPPO Iter3 показывает наивысшую выигрышную ставку. По сравнению с DPO и IPO, SPPO достигает превосходной производительности и эффективно контролирует длину вывода. Повторная ранжировка на этапе тестирования с использованием модели наград PairRM последовательно улучшает производительность модели без переоптимизации. SPPO превосходит многих современных чат-ботов на AlpacaEval 2.0 и остается конкурентоспособным с GPT-4 на MT-Bench.
Заключение
Статья представляет Self-Play Preference Optimization (SPPO), надежный метод для настройки LLM с использованием обратной связи от человека/ИИ. Путем использования самопроигрыша в игре для двух игроков и целевой обучения на основе предпочтений, SPPO значительно улучшает существующие методы, такие как DPO и IPO, на различных показателях. Интеграция модели предпочтений и пакетной оценки позволяет SPPO тесно соответствовать предпочтениям человека, решая проблемы, такие как «длинный биас» и взлом награды. Эти результаты предполагают потенциал SPPO для улучшения соответствия генеративной системы ИИ, а также аргументируют за его более широкое применение в LLM и за его пределами.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наш новостной бюллетень.
Не забудьте присоединиться к нашему субреддиту с 41 тысячей подписчиков.
Статья Self-Play Preference Optimization (SPPO): Инновационный подход машинного обучения к настройке больших языковых моделей (LLMs) отзывами от человека/ИИ впервые появилась на MarkTechPost.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Self-Play Preference Optimization (SPPO): An Innovative Machine Learning Approach to Finetuning Large Language Models (LLMs) from Human/AI Feedback.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизацию: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/itinai. Следите за новостями о ИИ в нашем Телеграм-канале t.me/itinainews или в Twitter @itinairu45358
Попробуйте AI Sales Bot https://itinai.ru/aisales. Этот AI ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от AI Lab itinai.ru будущее уже здесь!
«`




















