
Большие языковые модели (LLMs) сталкиваются с серьезными проблемами при решении сложных задач, несмотря на успехи, достигнутые с помощью метода цепочки рассуждений (CoT). Основная проблема заключается в вычислительных затратах, связанных с удлинением последовательностей CoT, что влияет на задержку вывода и требования к памяти.
Для решения этих вычислительных задач были разработаны различные методологии. Некоторые из них упрощают процесс рассуждения, пропуская определенные шаги, в то время как другие пытаются генерировать шаги параллельно. Также существует стратегия сжатия шагов рассуждения в непрерывные латентные представления, что позволяет моделям рассуждать без генерации явных токенов.
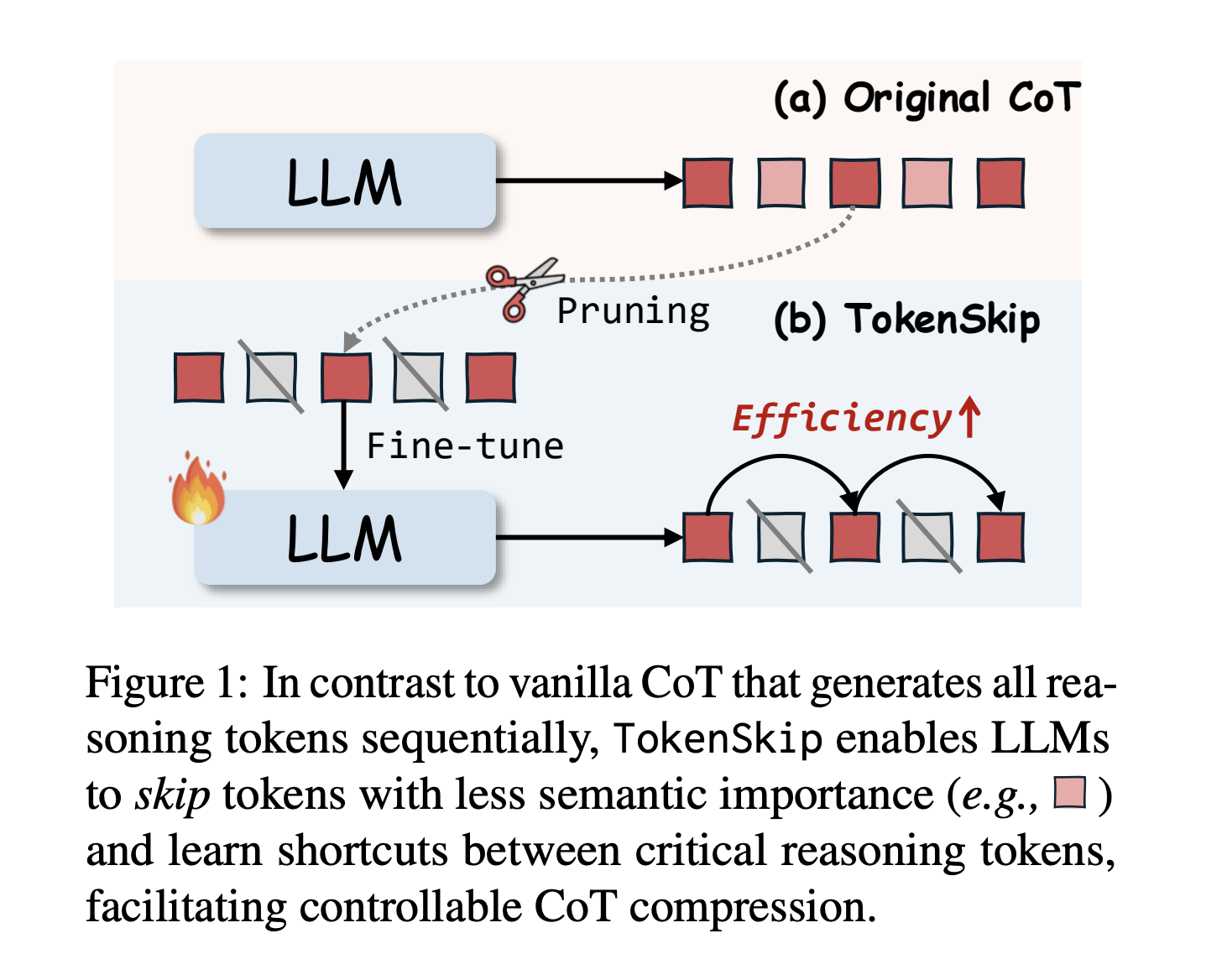
Исследователи из Гонконгского политехнического университета и Университета науки и технологий Китая предложили метод TokenSkip, который оптимизирует обработку CoT в LLM. Он позволяет моделям пропускать менее важные токены в последовательностях CoT, сохраняя связи между критически важными токенами. Система сначала создает сжатые данные для обучения, а затем проходит процесс дообучения. Первые тесты показывают обнадеживающие результаты, особенно в поддержании возможностей рассуждения при значительном снижении вычислительных затрат.
Архитектура TokenSkip основана на принципе, что различные токены рассуждения имеют разный уровень важности. Система проходит два основных этапа: подготовка данных для обучения и вывод. В фазе обучения генерируются траектории CoT, а оставшиеся траектории проходят процесс обрезки с помощью механизма «оценки важности». В процессе вывода TokenSkip сохраняет автогрессивный подход, но повышает эффективность, позволяя моделям пропускать менее важные токены.
Результаты показывают, что более крупные языковые модели лучше сохраняют производительность при достижении более высоких коэффициентов сжатия. Модель Qwen2.5-14B-Instruct достигает выдающихся результатов с минимальным снижением производительности и сокращением использования токенов на 40%. TokenSkip демонстрирует превосходные результаты по сравнению с альтернативными подходами, такими как сокращение на основе подсказок и обрезка.
В данной работе представлен метод TokenSkip, который представляет собой значительный шаг вперед в оптимизации обработки CoT для LLM, внедряя управляемый механизм сжатия на основе важности токенов. Успех метода заключается в поддержании точности рассуждения при значительном снижении вычислительных затрат путем выборочного сохранения критически важных токенов и пропуска менее значимых.
Изучите, как технологии искусственного интеллекта могут изменить ваш подход к работе. Найдите процессы, которые можно автоматизировать, и моменты взаимодействия с клиентами, где ИИ может добавить наибольшую ценность. Определите важные ключевые показатели, чтобы убедиться, что ваши инвестиции в ИИ приносят положительный результат.
Начните с небольшого проекта, соберите данные о его эффективности, а затем постепенно расширяйте использование ИИ в вашей работе. Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram.
Обратите внимание на пример решения на базе ИИ: бот для продаж, разработанный для автоматизации взаимодействия с клиентами круглосуточно и управления взаимодействиями на всех этапах пути клиента.



















