
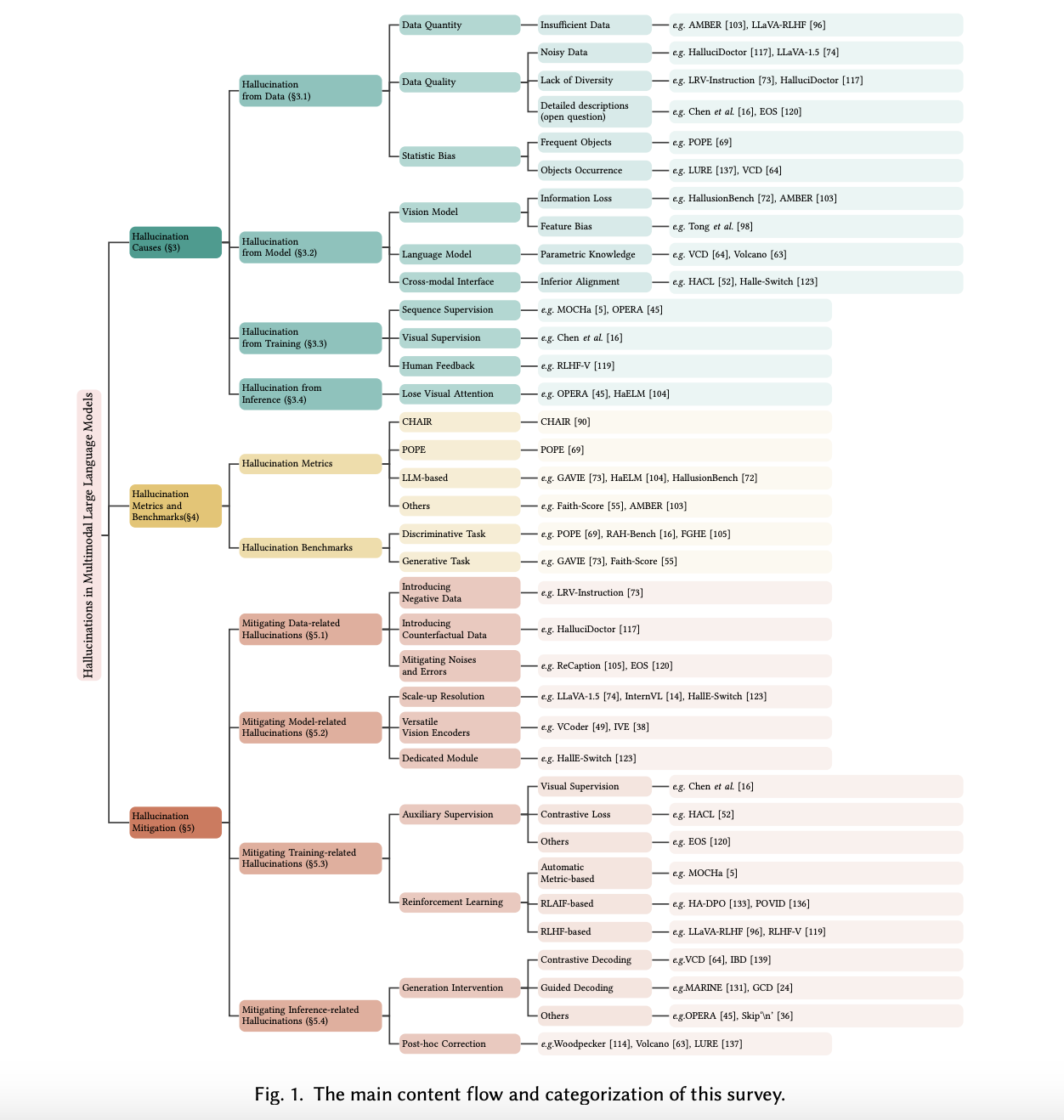
«`html
Новые стратегии снижения галлюцинаций в мультимодальных моделях языка
Мультимодальные крупные языковые модели (MLLM) представляют собой передовое пересечение обработки языка и компьютерного зрения, задача которых — понимать и генерировать ответы, учитывающие как текст, так и изображения. Эти модели способны выполнять задачи, требующие интегрированного подхода, такие как описание фотографий, ответы на вопросы о видео-контенте или помощь людям с нарушением зрения в ориентации в окружающей их среде.
Проблема галлюцинаций
Одной из наиболее актуальных проблем, с которой сталкиваются эти передовые модели, является «галлюцинация». Этот термин описывает ситуации, когда MLLM генерируют ответы, которые кажутся правдоподобными, но фактически неверны или не имеют основания в визуальном контенте, который они должны анализировать. Такие неточности могут подорвать доверие к приложениям ИИ, особенно в критических областях, таких как медицинский анализ изображений или системы наблюдения, где важна точность.
Решение проблемы
Усилия по устранению этих неточностей традиционно сосредотачивались на совершенствовании моделей через сложные тренировочные режимы с использованием обширных наборов аннотированных изображений и текстовых наборов данных. Однако проблема остается, в основном из-за сложностей обучения машин точно интерпретировать и коррелировать мультимодальные данные. Например, модель может описывать элементы на фотографии, которых на самом деле нет, неправильно интерпретировать действия на сцене или не распознавать контекст визуального ввода.
Исследователи из Национального университета Сингапура, Amazon Prime Video и AWS Shanghai AI Lab изучили методики снижения галлюцинаций. Один из подходов предполагает внедрение новых техник выравнивания в стандартную парадигму обучения, улучшающих способность модели коррелировать конкретные визуальные детали с точными текстовыми описаниями. Этот метод также включает критическую оценку качества данных, сосредоточившись на разнообразии и репрезентативности наборов данных для предотвращения распространенных данных, приводящих к галлюцинациям.
Количественные улучшения в нескольких ключевых показателях производительности подчеркивают эффективность изученных моделей. Например, в тестах, связанных с генерацией подписей к изображениям, усовершенствованные модели продемонстрировали снижение инцидентов галлюцинаций на 30% по сравнению с их предшественниками. Способность модели точно отвечать на визуальные вопросы улучшилась на 25%, отражая более глубокое понимание визуально-текстовых интерфейсов.
Заключение
Обзор мультимодальных крупных языковых моделей изучил значительное препятствие в виде галлюцинаций, которое является препятствием для создания полностью надежных систем ИИ. Предложенные решения улучшают технические возможности MLLM, а также расширяют их применимость в различных секторах, обещая будущее, в котором ИИ можно доверять в точной интерпретации и взаимодействии с визуальным миром. Этот набор работ намечает путь для будущих разработок в этой области и служит ориентиром для постоянных улучшений в мультимодальном понимании ИИ.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit с 42 тыс. подписчиков.
Исследование предоставлено MarkTechPost.