«`html
Оценка понимания языковых моделей временных зависимостей в процедурных текстах
Понимание того, как языковые модели глубокого обучения понимают естественные языковые планы, такие как инструкции и рецепты, является ключевым для их надежного использования в системах принятия решений. Критическим аспектом планов является их временное упорядочение, отражающее причинные связи между шагами. Планирование, неотъемлемое для процессов принятия решений, было широко изучено в различных областях, таких как робототехника и воплощенные среды. Эффективное использование, изменение или настройка планов требует способности рассуждать о вовлеченных шагах и их причинных связях. В то время как оценка в областях, таких как Blocksworld и симулированные среды, является обычной, планы на естественном языке в реальном мире представляют уникальные вызовы из-за их неспособности быть физически выполненными для проверки правильности и надежности.
Исследователи из Университета Стоуни-Брук, Военно-морской академии США и Университета Техаса в Остине разработали CAT-BENCH, бенчмарк для оценки способности передовых языковых моделей предсказывать последовательность шагов в кулинарных рецептах. Их исследование показывает, что текущие передовые языковые модели нуждаются в помощи в этой задаче, даже с использованием техник, таких как обучение с небольшим количеством данных и подсказки на основе объяснений, достигая низких показателей F1. Хотя эти модели могут генерировать последовательные планы, исследование подчеркивает значительные вызовы в понимании причинных и временных отношений в инструкционных текстах. Оценки показывают, что подача моделям запросов на объяснение их прогнозов после их генерации улучшает производительность по сравнению с традиционной подачей цепочки мыслей, выявляя несоответствия в рассуждениях модели.
Ранние исследования подчеркивали понимание планов и целей. Генерация планов включает временное рассуждение и отслеживание состояний сущностей. NaturalPlan фокусируется на нескольких задачах реального мира, включающих взаимодействие на естественном языке. PlanBench продемонстрировал вызовы в разработке эффективных планов в рамках строгого синтаксиса — модели задачи конструирования сценария, ориентированные на цель, для создания последовательностей шагов для конкретных целей. ChattyChef использует разговорные настройки для уточнения порядка шагов. CoPlan пересматривает шаги для соответствия ограничениям. Исследования, такие как состояния сущностей, связь действий и предсказание следующего события, исследуют понимание планов. Различные наборы данных рассматривают зависимости в инструкциях и разветвления принятия решений. Однако необходимо больше наборов данных, фокусирующихся на предсказании и объяснении временных ограничений порядка в инструкционных планах.
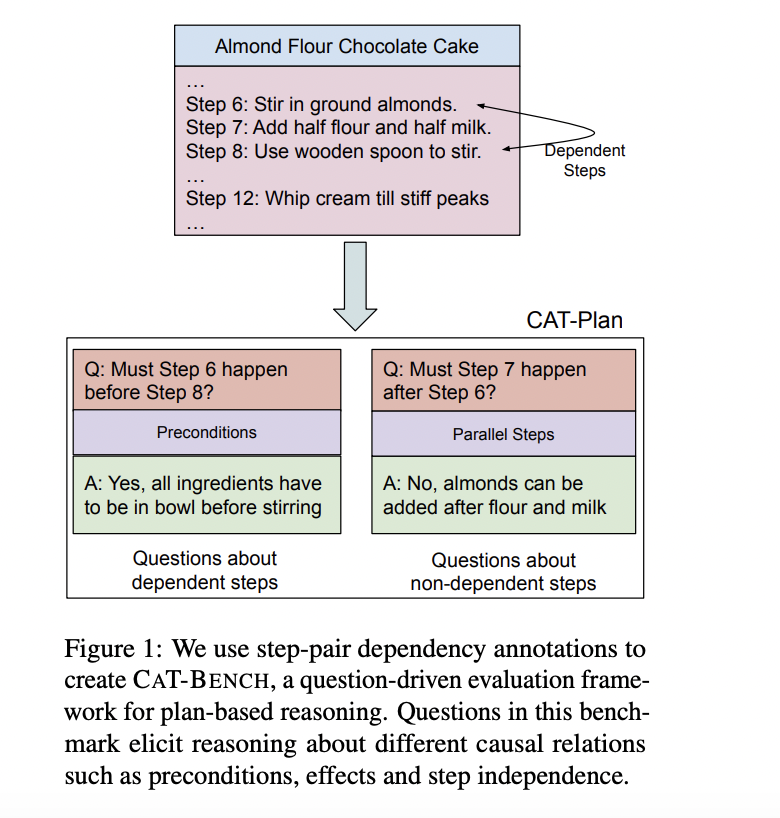
CAT-BENCH оценивает способность моделей распознавать временные зависимости между шагами в кулинарных рецептах. Основываясь на причинных связях в направленном ациклическом графе (DAG) рецепта, он задает вопросы о том, должен ли один шаг произойти до или после другого. Например, определение того, должно ли размещение теста на противень предшествовать извлечению испеченного торта для остывания, зависит от понимания предусловий и эффектов шага. CAT-BENCH содержит 2 840 вопросов по 57 рецептам, равномерно разделенных между вопросами, проверяющими временные отношения «до» и «после». Модели оцениваются по их точности, полноте и показателю F1 в предсказании этих зависимостей, а также их способности предоставлять действительные объяснения своим суждениям.
Различные модели были оценены на CAT-BENCH по их производительности в предсказании зависимостей шагов. В нулевом сценарии GPT-4-turbo и GPT-3.5-turbo показали самые высокие показатели F1, при этом GPT-4o показал неожиданно худшие результаты. Добавление объяснений к ответам в целом улучшило производительность модели, заметно улучшив показатель F1 у GPT-4o. Однако модели были склонны к предсказанию зависимостей, что сказалось на общем балансе точности и полноты. Человеческая оценка объяснений, сгенерированных моделями, показала различное качество, причем более крупные модели в целом превосходили более маленькие. Модели нуждались в последовательности в предсказании порядка шагов, особенно при добавлении объяснений. Дополнительный анализ выявил распространенные ошибки, такие как непонимание многопереходных зависимостей и неспособность определить причинные связи между шагами.
CAT-BENCH представляет новый бенчмарк для оценки способностей языковых моделей понимать причинные и временные отношения в процедурных текстах, таких как кулинарные рецепты. Несмотря на продвижения в передовых моделях (LLM), ни одна из них точно не определяет, должен ли один шаг в плане предшествовать или следовать за другим, особенно в распознавании независимостей. Модели также проявляют несогласованность в своих прогнозах. Подача запросов на ответ от LLM, за которым следует объяснение, значительно улучшает их производительность по сравнению с рассуждением, за которым следует ответ. Однако человеческая оценка этих объяснений показывает значительное пространство для улучшения понимания моделей зависимостей шагов. Эти результаты подчеркивают текущие ограничения LLM для приложений, основанных на планах.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 45 тыс. подписчиков на Reddit о машинном обучении.
«`


















