
«`html
DetoxBench: Comprehensive Evaluation of Large Language Models for Effective Detection of Fraud and Abuse Across Diverse Real-World Scenarios
Несколько значимых критериев были разработаны для оценки понимания языка и конкретных применений больших языковых моделей (LLM). Известные критерии включают GLUE, SuperGLUE, ANLI, LAMA, TruthfulQA и Persuasion for Good, которые оценивают LLM по задачам, таким как анализ настроения, здравый смысл и фактическая точность. Однако ограниченная работа была направлена на обнаружение мошенничества и злоупотреблений с использованием LLM, из-за ограниченной доступности данных и распространенности числовых наборов данных, не подходящих для обучения LLM.
Оценка мошенничества и злоупотреблений с использованием LLM
Недостаток общедоступных наборов данных и сложности в текстовом представлении шаблонов мошенничества подчеркнули необходимость специализированной системы оценки. Эти ограничения побудили к разработке более целенаправленных исследований и ресурсов для улучшения обнаружения и смягчения вредоносного языка с использованием LLM. Новое исследование ИИ от Amazon представляет новый подход к решению этих проблем и продвижению возможностей LLM в обнаружении мошенничества и злоупотреблений.
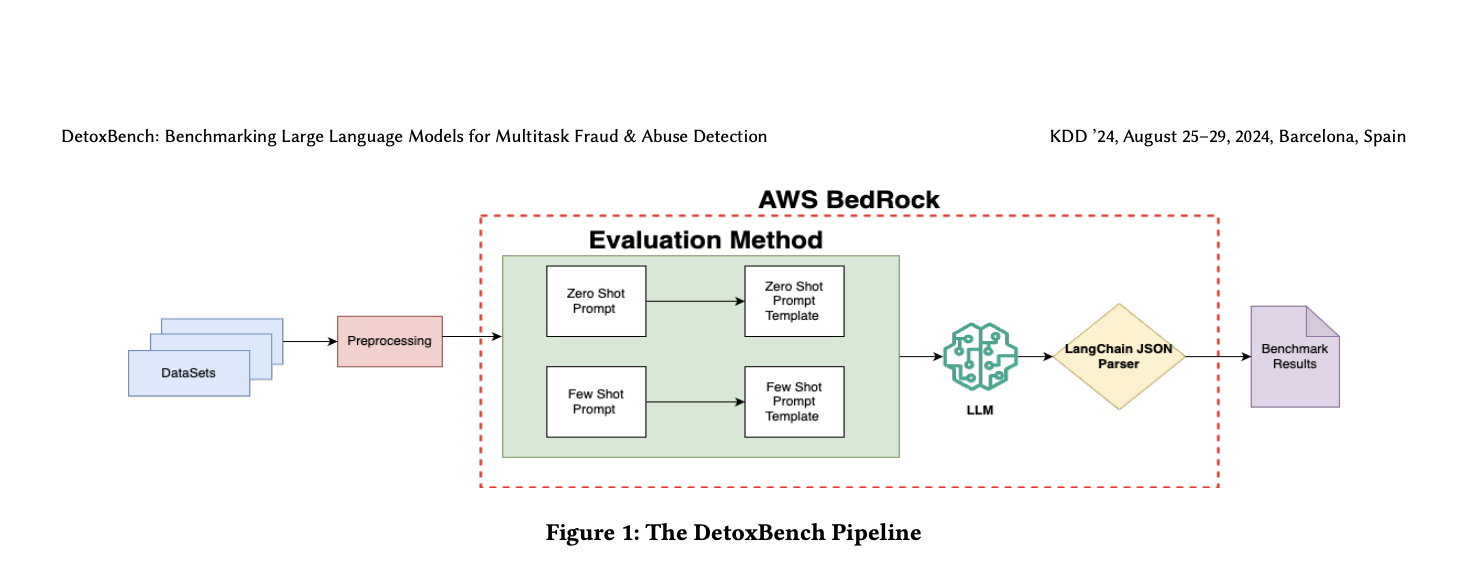
Исследователи представляют «DetoxBench» — комплексную оценку LLM для обнаружения мошенничества и злоупотреблений, рассматривая их потенциал и вызовы. Статья подчеркивает возможности LLM в обработке естественного языка, но указывает на необходимость дальнейшего изучения в высокостейкних областях, таких как обнаружение мошенничества. Она также отмечает общественный вред, наносимый мошенничеством, текущую зависимость от традиционных моделей и отсутствие всеобъемлющих критериев для LLM в этой области. Цель комплексной системы оценки — оценить эффективность LLM, способствовать развитию этичного ИИ и смягчить вред в реальном мире.
Методика DetoxBench включает разработку комплексной системы оценки, направленной на оценку LLM в обнаружении и смягчении мошенничества и злоупотреблений. Система включает задачи, такие как обнаружение спама, выявление ненавистнической речи и идентификация мизогинного языка, отражающие реальные вызовы. Несколько передовых LLM, включая те, что от Anthropic, Mistral AI и AI21, были выбраны для оценки, обеспечивая комплексную оценку способностей различных моделей в обнаружении мошенничества и злоупотреблений.
Эксперименты подчеркивают разнообразие задач для оценки обобщения LLM в различных сценариях обнаружения мошенничества и злоупотреблений. Метрики производительности анализируются для выявления сильных и слабых сторон моделей, особенно в задачах, требующих тонкого понимания. Сравнительный анализ показывает изменчивость производительности LLM, указывая на необходимость дальнейшего совершенствования для высокостейких приложений. Полученные результаты подчеркивают важность постоянного развития и ответственного внедрения LLM в критических областях, таких как обнаружение мошенничества.
Оценка DetoxBench восьми больших языковых моделей (LLM) в различных задачах обнаружения мошенничества и злоупотреблений выявила значительные различия в производительности. Модель Mistral Large показала самые высокие показатели F1 в пяти из восьми задач, демонстрируя свою эффективность. Модели Anthropic Claude проявили высокую точность, превышающую 90% в некоторых задачах, но обладали заметно низким полнотой, опускаясь ниже 10% для обнаружения токсичного чата и ненавистнической речи. Модели Cohere показали высокую полноту — 98% для обнаружения мошеннических электронных писем, но более низкую точность — 64%, что привело к более высокой частоте ложноположительных срабатываний. Время вывода варьировалось: модели AI21 были самыми быстрыми — 1,5 секунды на экземпляр, в то время как модели Mistral Large и Anthropic Claude занимали примерно 10 секунд на экземпляр.
Несколько промптов с ограниченным улучшением по сравнению с нулевыми промптами привели к конкретным улучшениям в задачах, таких как обнаружение фальшивых вакансий и выявление мизогинии. Дисбалансированные наборы данных, содержащие меньше случаев злоупотреблений, были скорректированы случайной недоотборкой, создавая сбалансированные тестовые наборы для более точной оценки. Проблемы с соответствием формата исключили модели, такие как Command R от Cohere, из окончательных результатов. Эти результаты подчеркивают важность выбора модели, специфичной для задачи, и предполагают, что доработка LLM может дальше улучшить их производительность в обнаружении мошенничества и злоупотреблений.
В заключение, DetoxBench создает первую систематическую оценку для оценки LLM в обнаружении мошенничества и злоупотреблений, раскрывая ключевые аспекты производительности модели. Большие модели, такие как 200-миллиардная Anthropic и 176-миллиардная семьи Mistral AI, проявили себя, особенно в контекстном понимании. Исследование показало, что несколько промптов часто не превосходили нулевые промпты, что указывает на изменчивость эффективности промптов. Будущие исследования нацелены на доработку LLM и изучение передовых техник, подчеркивая важность тщательного выбора модели и стратегии для улучшения возможностей обнаружения в этой критической области.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и LinkedIn. Присоединяйтесь к нашему Телеграм-каналу. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 50 тыс. подписчиков на Reddit
Источник: MarkTechPost
«`




















