
Sequential-NIAH: Оценка LLM в Извлечении Последовательной Информации из Длинных Текстов
Оценка способности LLM обрабатывать длинные контексты имеет критическое значение, особенно для извлечения конкретной и актуальной информации из объемных текстов. Современные модели, такие как Gemini-1.5, GPT-4 и другие, стремятся увеличить длину контекста, сохраняя при этом высокие способности к рассуждению. Для оценки этих возможностей были разработаны бенчмарки, такие как ∞Bench и LongBench. Однако они часто не учитывают задачу NIAH, которая ставит перед моделями задачу извлечения ключевой информации из в основном нерелевантного содержания.
Проблемы Оценки и Решения
Ранее существовавшие бенчмарки, такие как RULER и Counting-Stars, использовали упрощенные сценарии для NIAH, однако NeedleBench улучшил ситуацию, добавив более реалистичные задачи. Тем не менее, до сих пор отсутствуют задачи, включающие извлечение и правильную последовательность информации, такой как временные метки или пошаговые инструкции.
Введение в Sequential-NIAH
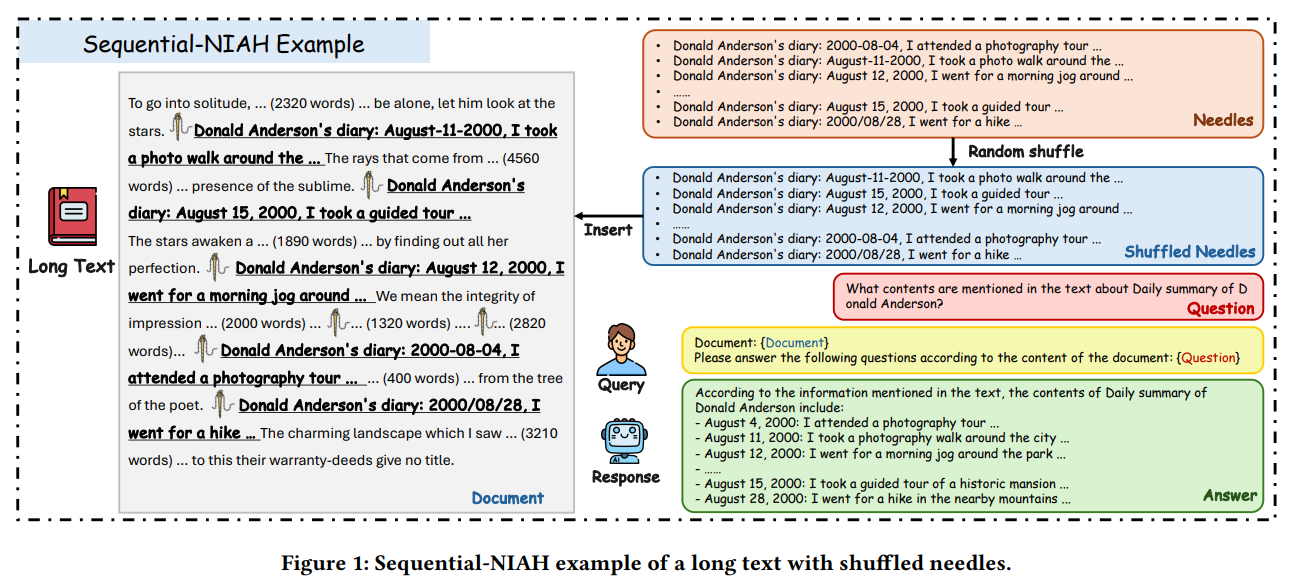
Исследователи из Tencent YouTu Lab разработали Sequential-NIAH, бенчмарк, предназначенный для оценки способности LLM извлекать последовательную информацию из длинных текстов. Бенчмарк включает 14,000 образцов, охватывающих контексты от 8K до 128K токенов. Модель, обученная на синтетических данных, достигла 99.49% точности в оценке правильности и порядка ответов.
Структура и Методология
Бенчмарк Sequential-NIAH использует три типа QA-синтезов: синтетические, реальные и открытые. Эти QA-пары внедряются в разнообразные длинные тексты, что позволяет создать 14,000 образцов для обучения, разработки и тестирования на английском и китайском языках.
Результаты Оценки
Модель была протестирована на популярных LLM, таких как Claude-3.5 и GPT-4o, и достигла 99.49% точности. Однако в тестах на 2,000 образцах Gemini-1.5 показала наилучший результат с точностью 63.15%. Эти результаты подчеркивают сложность задачи и необходимость дальнейших улучшений в понимании длинного контекста.
Заключение
Бенчмарк Sequential-NIAH позволяет оценивать LLM на их способность извлекать последовательную информацию из длинных текстов и подчеркивает проблемы, связанные с увеличением длины контекстов и количеством игл. Это делает его ценным инструментом для дальнейшего прогресса в исследовании LLM.
Практические Решения для Бизнеса
Ищите возможности для автоматизации процессов и взаимодействий с клиентами, где искусственный интеллект может добавить максимальную ценность.
Определите ключевые показатели эффективности (KPI), чтобы убедиться, что ваши инвестиции в ИИ действительно положительно сказываются на бизнесе.
Выбирайте инструменты, соответствующие вашим потребностям, и настраивайте их под свои цели.
Начните с небольшого проекта, собирайте данные о его эффективности и постепенно расширяйте использование ИИ в своей работе.
Контакты
Если вам нужна помощь в управлении ИИ в бизнесе, свяжитесь с нами по адресу hello@itinai.ru. Чтобы быть в курсе последних новостей ИИ, подписывайтесь на наш Telegram.
Пример ИИ-Решения
Посмотрите на практический пример решения на базе ИИ: бот для продаж от itinai.ru/aisales, предназначенный для автоматизации общения с клиентами и управления взаимодействиями на всех этапах пути клиента.





















