«`html
Искусственный интеллект в Windows Agent Arena (WAA)
Искусственный интеллект (ИИ) продвигается в разработке агентов, способных выполнять сложные задачи на цифровых платформах. Эти агенты, часто основанные на больших языковых моделях (LLM), имеют потенциал значительно повысить производительность человека, автоматизируя задачи в операционных системах. Агенты ИИ, способные воспринимать, планировать и действовать в средах, таких как операционная система Windows (OS), предлагают огромную ценность как для личных, так и для профессиональных задач, которые все больше переходят в цифровую сферу. Возможность этих агентов взаимодействовать с различными приложениями и интерфейсами означает, что они могут обрабатывать задачи, которые обычно требуют человеческого контроля, в конечном итоге нацеливаясь на более эффективное взаимодействие человека с компьютером.
Проблема и практические решения
Одной из значительных проблем в разработке таких агентов является точная оценка их производительности в условиях, отражающих реальный мир. В то время как они эффективны в конкретных областях, таких как навигация в Интернете или задачи на основе текста, большинство существующих бенчмарков не улавливают сложность и разнообразие задач, с которыми реальные пользователи сталкиваются ежедневно на платформах, таких как Windows. Для устранения этого разрыва необходимы инструменты, способные тестировать способности агентов в более динамичных, многоэтапных задачах в различных областях в масштабируемой манере. Более того, текущие инструменты не могут эффективно параллелизировать задачи, из-за чего полные оценки занимают дни, а не минуты.
Ряд бенчмарков был разработан для оценки агентов ИИ, включая OSWorld, который в основном фокусируется на задачах, связанных с Linux. В то время как эти платформы предоставляют полезные исследования производительности агентов, они плохо масштабируются для мульти-модальных сред, таких как Windows. Другие фреймворки, такие как WebLinx и Mind2Web, оценивают способности агентов в веб-средах, но им не хватает глубины для полноценного тестирования поведения агентов в более сложных, основанных на ОС рабочих процессах. Эти ограничения подчеркивают необходимость бенчмарка, который охватывает полный спектр взаимодействия человека с компьютером в широко используемой ОС, такой как Windows, обеспечивая быструю оценку через облачную параллелизацию.
Исследователи из Microsoft, Карнеги-Меллоновского университета и Колумбийского университета представили WindowsAgentArena, комплексный и воспроизводимый бенчмарк, специально разработанный для оценки агентов ИИ в среде ОС Windows. Этот инновационный инструмент позволяет агентам работать в реальной ОС Windows, взаимодействуя с приложениями, инструментами и веб-браузерами, повторяя задачи, которые обычно выполняют человеческие пользователи. Используя масштабируемую облачную инфраструктуру Azure, платформа может параллелизировать оценки, позволяя полный запуск бенчмарка всего за 20 минут, в отличие от дней, требуемых для оценок по ранее использовавшимся методам. Эта параллелизация увеличивает скорость оценок и обеспечивает более реалистичное поведение агентов, позволяя им взаимодействовать с различными инструментами и средами одновременно.
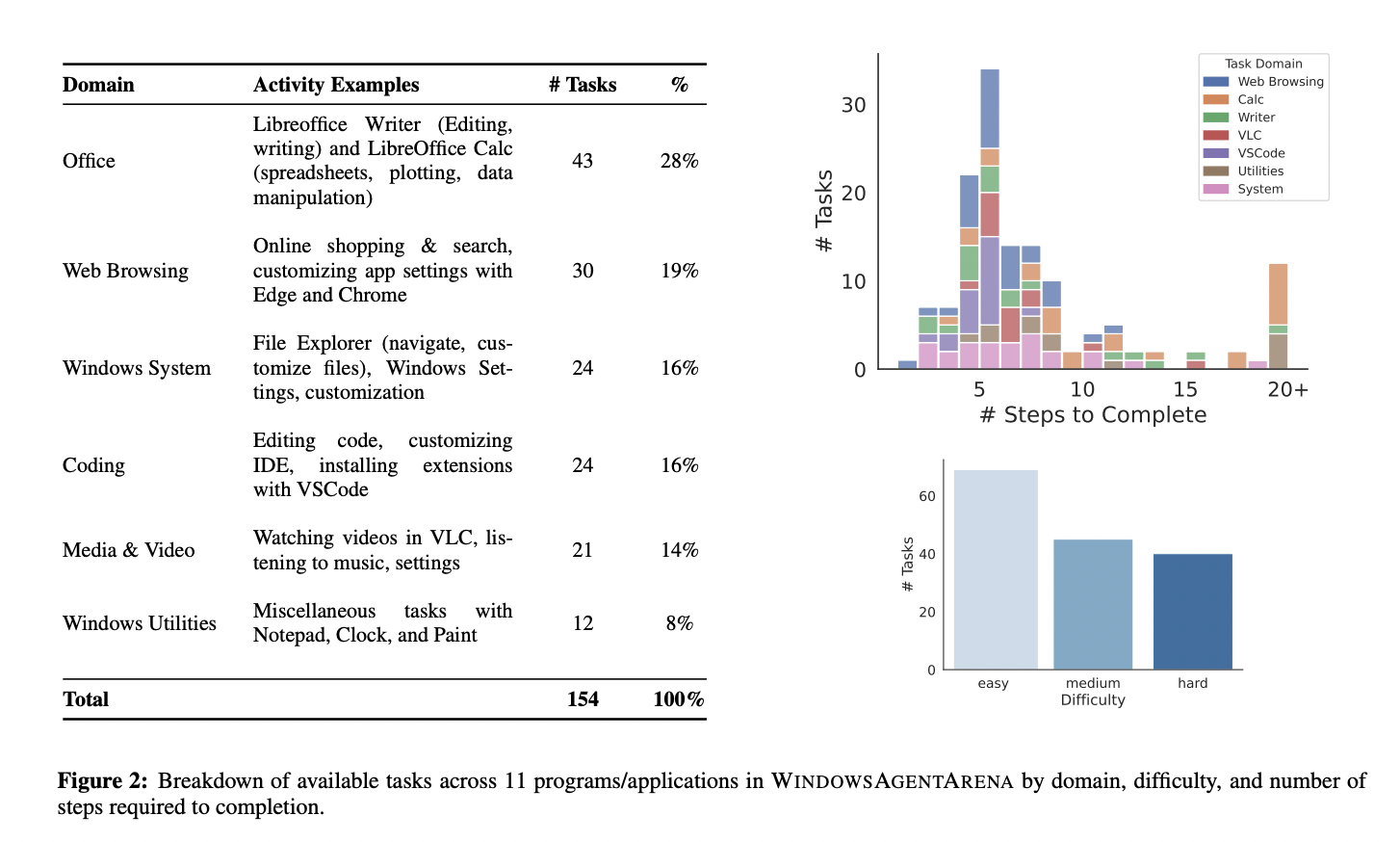
Набор бенчмарков включает более 154 разнообразных задач, охватывающих несколько областей, включая редактирование документов, веб-браузинг, управление системой, программирование и потребление медиа. Эти задачи тщательно разработаны для отражения повседневных рабочих процессов в Windows, при этом агентам требуется выполнять многоэтапные задачи, такие как создание ярлыков для документов, навигация по файловым системам и настройка параметров в сложных приложениях, таких как VSCode и LibreOffice Calc. WindowsAgentArena также вводит новый критерий оценки, который награждает агентов на основе завершения задач, а не простого следования предзаписанным демонстрациям человека, что позволяет более гибкое и реалистичное выполнение задач. Бенчмарк может легко интегрироваться с контейнерами Docker, обеспечивая безопасную среду для тестирования и позволяя исследователям масштабировать свои оценки на нескольких агентах.
Для демонстрации эффективности WindowsAgentArena исследователи разработали нового мульти-модального агента ИИ под названием Navi. Navi разработан для автономной работы в ОС Windows, используя комбинацию цепочки мыслей и мульти-модального восприятия для выполнения задач. Исследователи протестировали Navi на бенчмарке WindowsAgentArena, где агент достиг процента успешных выполнений в 19,5%, что значительно ниже, чем 74,5% успешных выполнений у непомощенных людей. Хотя эта производительность подчеркивает сложности агентов ИИ в воспроизведении эффективности, характерной для человека, она также подчеркивает потенциал для улучшения по мере развития этих технологий. Navi также продемонстрировал хорошую производительность во вторичном веб-бенчмарке Mind2Web, дополнительно подтверждая его адаптивность в различных средах.
Методы, используемые для улучшения производительности Navi, заслуживают внимания. Агент полагается на визуальные маркеры и техники анализа экрана, такие как Set-of-Marks (SoMs), для понимания и взаимодействия с графическими аспектами экрана. Эти SoMs позволяют агенту точно идентифицировать кнопки, значки и текстовые поля, что делает его более эффективным в выполнении задач, которые включают несколько этапов или требуют детальной навигации по экрану. Navi получает выгоду от анализа дерева UIA, метода, извлекающего видимые элементы из дерева автоматизации пользовательского интерфейса Windows, обеспечивающего более точное взаимодействие агента.
В заключение, WindowsAgentArena является значительным прорывом в оценке агентов ИИ в реальных средах операционных систем. Он устраняет ограничения предыдущих бенчмарков, предлагая масштабируемую, воспроизводимую и реалистичную платформу тестирования, позволяющую быстрые, параллельные оценки агентов в экосистеме ОС Windows. Благодаря разнообразию задач и инновационным метрикам оценки, этот бенчмарк предоставляет исследователям и разработчикам инструменты для расширения границ развития агентов ИИ. Производительность Navi, хотя и пока не соответствует эффективности человека, демонстрирует потенциал бенчмарка в ускорении прогресса в исследованиях мульти-модальных агентов. Его передовые техники восприятия, такие как SoMs и анализ UIA, дополнительно прокладывают путь для более способных и эффективных агентов ИИ в будущем.
Проверьте статью, код и страницу проекта. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Твиттер и присоединиться к нашему каналу в Телеграме и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
БЕСПЛАТНЫЙ ВЕБИНАР ПО ИИ: «SAM 2 для видео: как настроить на ваших данных» (Ср, 25 сентября, 4:00 — 4:45 EST)
Опубликовано на MarkTechPost.
«`




















